
Planet Python
Last update: April 01, 2025 01:43 PM UTC
April 01, 2025
Zero to Mastery
[March 2025] Python Monthly Newsletter 🐍
64th issue of Andrei Neagoie's must-read monthly Python Newsletter: Django Got Forked, The Science of Troubleshooting, Python 3.13 TLDR, and much more. Read the full newsletter to get up-to-date with everything you need to know from last month.
Tryton News
Newsletter April 2025

Last month we focused on fixing bugs, improving the behaviour of things, speeding-up performance issues - building on the changes from our last release. We also added some new features which we would like to introduce to you in this newsletter.
For an in depth overview of the Tryton issues please take a look at our issue tracker or see the issues and merge requests filtered by label.
Changes for the User
CRM, Sales, Purchases and Projects
Now we notify the user when trying to add a duplicate contact mechanism.
Add quotation validity date on sale and purchase quotations.
On sale we compute the validity date when it goes to state quotation and display the validity date in the report. On purchase we set the date directly.
It is a common practice among other things to answer a complain by giving a promotion coupon to the customer. Now the user can create a coupon from the sale complain as an action.
We now use the actual quantity of a sale line when executing a sale complaint,
when the product is already selected.
Now we add an relate to open all products of sales, to be able to check all the sold products (for quantity or price).
We simplify the coupon number management and added a menu entry for promotion coupon numbers.
Now we display a coupon form on promotions and we remove the name field on promotion coupons.
Accounting, Invoicing and Payments
Now we allow to download all pending SEPA messages in a single message report.
We now replace the maturity date on account move by a combined payable/receivable date field which contains a given maturity date and if it is empty, falls back to the effective date. This provides a better chronology of the move lines.
On account move we now replace the post_number by the number-field. The original functionality of the number field, - delivering a sequential number for account moves in draft state, - is replaced by the account move id.
We now add some common payment terms:
- Upon Receipt
- Net 10, 15, 30, 60 days
- Net 30, 60 days End of Month
- End of Month
- End of Month Following
Now we display an optional company-field on the payment and group list.
We now add tax identifiers to the company. A company may have two tax identifiers, one used for transactions inland and another used abroad. Now it is possible to select the company tax identifier based on rules.
Now we make the deposit-field optional on party list view.
We now use the statement date to compute the start balance instead of always using the last end balance.
Now we make entries in analytic accounting read-only depending on their origin state.
We now allow to delete landed costs only if they are cancelled.
Now we add the company field optionally to the SEPA mandate list.
Stock, Production and Shipments
We now add the concept of product place also to the inventory line, because some users may want to see the place when doing inventory so they know where to count the products exactly.
Now we display the available quantity when searching in a stock move
and if the product is already selected:
We now ship packages of internal shipments with transit.
Now we do no longer force to fill an incoterm when shipping inside Europe.
User Interface
In the web client now we scroll to the first selected element in the tree view, when switching from form view.
Now we add a color widget to the form view.

Also we now add an icon of type
color, to display the color visually in a tree view. We extend the image type to add color which just displays an image filled with color.
Now we deactivate the open-button of the One2Many widget, if there is no form view.
In the desktop client we now include the version number on the new version available message.
System Data and Configuration
In the web user form we now use the same structure as in user form.
Now we make the product attribute names unique. Because the name of the attributes are used as keys of a fields.Dict.
We now add the Yapese currency Rai.
Now we order the incoming documents by their descending ID, with the most recent documents on top.
New Documentation
Now we add an example of a payment term with multiple deltas.
We now reworked the web_shop_shopify module documentation.
New Releases
We released bug fixes for the currently maintained long term support series
7.0 and 6.0, and for the penultimate series 7.4 and 7.2.
Changes for Implementers and Developers
Now we raise UserErrors from the database exceptions, to log more information on data and integrity errors.
In the desktop client we now remove the usage of GenericTreeModel, the last remaining part of pygtkcompat in Tryton.
We now make it easy to extend the Sendcloud sender address with a pattern.
Now we set a default value for all fields of a wizard state view.
If the client does not display a field of a state view, the value of this field on the instance record is not a defined attribute. So we need to access it using getattr with a default value, but in theory this can happen for any state in any record as user can extend any view.
We now store the last version series to which the database was updated in ir.configuration. With this information, the list of databases is filtered to the same client series. The remote access to a database is restricted to databases available in the list. We now also return the series instead of the version for remote call.
Authors: @dave @pokoli @udono spoiler
1 post - 1 participant
Wingware
Wing Python IDE 11 Early Access - March 27, 2025
Wing 11 is now available as an early access release, with improved AI assisted development, support for the uv package manager, improved Python code analysis, improved custom key binding assignment user interface, improved diff/merge, a new preference to auto-save files when Wing loses the application focus, updated German, French and Russian localizations (partly using AI), a new experimental AI-driven Spanish localization, and other bug fixes and minor improvements.
You can participate in the early access program simply by downloading the early access releases. We ask only that you keep your feedback and bug reports private by submitting them through Wing's Help menu or by emailing us at support@wingware.com.
Downloads
Wing 10 and earlier versions are not affected by installation of Wing 11 and may be installed and used independently. However, project files for Wing 10 and earlier are converted when opened by Wing 11 and should be saved under a new name, since Wing 11 projects cannot be opened by older versions of Wing.
 New in Wing 11
New in Wing 11
Improved AI Assisted Development
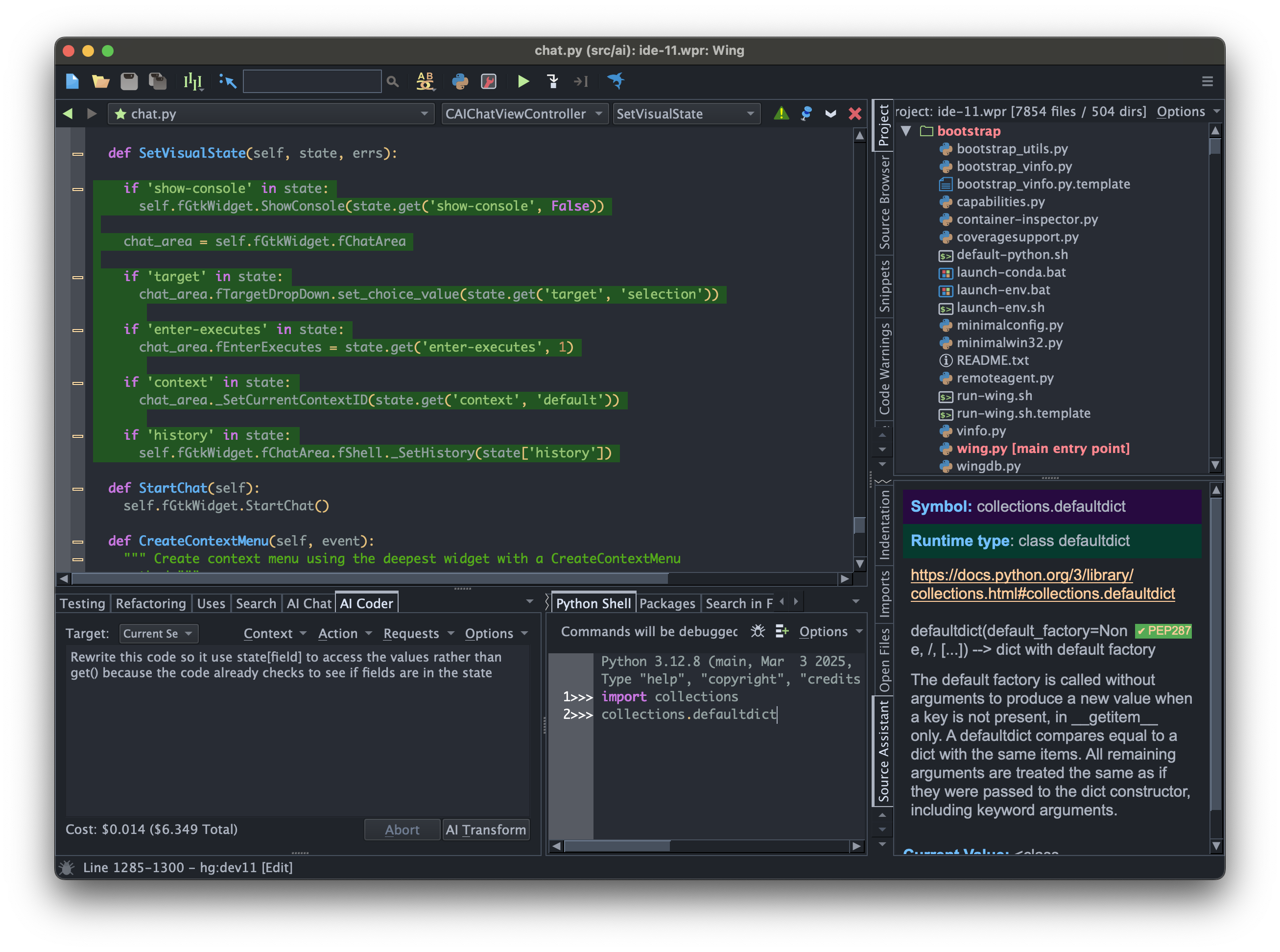
Wing 11 improves the user interface for AI assisted development by introducing two separate tools AI Coder and AI Chat. AI Coder can be used to write, redesign, or extend code in the current editor. AI Chat can be used to ask about code or iterate in creating a design or new code without directly modifying the code in an editor.
This release also improves setting up AI request context, so that both automatically and manually selected and described context items may be paired with an AI request. AI request contexts can now be stored, optionally so they are shared by all projects, and may be used independently with different AI features.
AI requests can now also be stored in the current project or shared with all projects, and Wing comes preconfigured with a set of commonly used requests. In addition to changing code in the current editor, stored requests may create a new untitled file or run instead in AI Chat. Wing 11 also introduces options for changing code within an editor, including replacing code, commenting out code, or starting a diff/merge session to either accept or reject changes.
Wing 11 also supports using AI to generate commit messages based on the changes being committed to a revision control system.
You can now also configure multiple AI providers for easier access to different models. However, as of this release, OpenAI is still the only supported AI provider and you will still need a paid OpenAI account and API key. We recommend paying for Tier 2 or better rate limits.
For details see AI Assisted Development under Wing Manual in Wing 11's Help menu.
Package Management with uv
Wing Pro 11 adds support for the uv package manager in the New Project dialog and the Packages tool.
For details see Project Manager > Creating Projects > Creating Python Environments and Package Manager > Package Management with uv under Wing Manual in Wing 11's Help menu.
Improved Python Code Analysis
Wing 11 improves code analysis of literals such as dicts and sets, parametrized type aliases, typing.Self, type variables on the def or class line that declares them, generic classes with [...], and __all__ in *.pyi files.
Updated Localizations
Wing 11 updates the German, French, and Russian localizations, and introduces a new experimental AI-generated Spanish localization. The Spanish localization and the new AI-generated strings in the French and Russian localizations may be accessed with the new User Interface > Include AI Translated Strings preference.
Improved diff/merge
Wing Pro 11 adds floating buttons directly between the editors to make navigating differences and merging easier, allows undoing previously merged changes, and does a better job managing scratch buffers, scroll locking, and sizing of merged ranges.
For details see Difference and Merge under Wing Manual in Wing 11's Help menu.
Other Minor Features and Improvements
Wing 11 also improves the custom key binding assignment user interface, adds a Files > Auto-Save Files When Wing Loses Focus preference, warns immediately when opening a project with an invalid Python Executable configuration, allows clearing recent menus, expands the set of available special environment variables for project configuration, and makes a number of other bug fixes and usability improvements.
Changes and Incompatibilities
Since Wing 11 replaced the AI tool with AI Coder and AI Chat, and AI configuration is completely different than in Wing 10, so you will need to reconfigure your AI integration manually in Wing 11. This is done with Manage AI Providers in the AI menu or the Options menu in either AI tool. After adding the first provider configuration, Wing will set that provider as the default.
If you have questions about any of this, please don't hesitate to contact us at support@wingware.com.
Glyph Lefkowitz
A Bigger Database
A Database File
When I was 10 years old, and going through a fairly difficult time, I was lucky enough to come into the possession of a piece of software called Claris FileMaker Pro™.
FileMaker allowed its users to construct arbitrary databases, and to associate their tables with a customized visual presentation. FileMaker also had a rudimentary scripting language, which would allow users to imbue these databases with behavior.
As a mentally ill pre-teen, lacking a sense of control over anything or anyone in my own life, including myself, I began building a personalized database to catalogue the various objects and people in my immediate vicinity. If one were inclined to be generous, one might assess this behavior and say I was systematically taxonomizing the objects in my life and recording schematized information about them.
As I saw it at the time, if I collected the information, I could always use it later, to answer questions that I might have. If I didn’t collect it, then what if I needed it? Surely I would regret it! Thus I developed a categorical imperative to spend as much of my time as possible collecting and entering data about everything that I could reasonably arrange into a common schema.
Having thus summoned this specter of regret for all lost data-entry opportunities, it was hard to dismiss. We might label it “Claris’s Basilisk”, for obvious reasons.
Therefore, a less-generous (or more clinically-minded) observer might have replaced the word “systematically” with “obsessively” in the assessment above.
I also began writing what scripts were within my marginal programming abilities at the time, just because I could: things like computing the sum of every street number of every person in my address book. Why was this useful? Wrong question: the right question is “was it possible” to which my answer was “yes”.
If I was obliged to collect all the information which I could observe — in case it later became interesting — I was similarly obliged to write and run every program I could. It might, after all, emit some other interesting information.
I was an avid reader of science fiction as well.
I had this vague sense that computers could kind of think. This resulted in a chain of reasoning that went something like this:
- human brains are kinda like computers,
- the software running in the human brain is very complex,
- I could only write simple computer programs, but,
- when you really think about it, a “complex” program is just a collection of simpler programs
Therefore: if I just kept collecting data, collecting smaller programs that could solve specific problems, and connecting them all together in one big file, eventually the database as a whole would become self-aware and could solve whatever problem I wanted. I just needed to be patient; to “keep grinding” as the kids would put it today.
I still feel like this is an understandable way to think — if you are a highly depressed and anxious 10-year-old in 1990.
Anyway.
35 Years Later
OpenAI is a company that produces transformer architecture machine learning generative AI models; their current generation was trained on about 10 trillion words, obtained in a variety of different ways from a large variety of different, unrelated sources.
A few days ago, on March 26, 2025 at 8:41 AM Pacific Time, Sam Altman took to “X™, The Everything App™,” and described the trajectory of his career of the last decade at OpenAI as, and I quote, a “grind for a decade trying to help make super-intelligence to cure cancer or whatever” (emphasis mine).
I really, really don’t want to become a full-time AI skeptic, and I am not an expert here, but I feel like I can identify a logically flawed premise when I see one.
This is not a system-design strategy. It is a trauma response.
You can’t cure cancer “or whatever”. If you want to build a computer system that does some thing, you actually need to hire experts in that thing, and have them work to both design and validate that the system is fit for the purpose of that thing.
Aside: But... are they, though?
I am not an oncologist; I do not particularly want to be writing about the specifics here, but, if I am going to make a claim like “you can’t cure cancer this way” I need to back it up.
My first argument — and possibly my strongest — is that cancer is not cured.
QED.
But I guess, to Sam’s credit, there is at least one other company partnering with OpenAI to do things that are specifically related to cancer. However, that company is still in a self-described “initial phase” and it’s not entirely clear that it is going to work out very well.
Almost everything I can find about it online was from a PR push in the middle of last year, so it all reads like a press release. I can’t easily find any independently-verified information.
A lot of AI hype is like this. A promising demo is delivered; claims are made that surely if the technology can solve this small part of the problem now, within 5 years surely it will be able to solve everything else as well!
But even the light-on-content puff-pieces tend to hedge quite a lot. For example, as the Wall Street Journal quoted one of the users initially testing it (emphasis mine):
The most promising use of AI in healthcare right now is automating “mundane” tasks like paperwork and physician note-taking, he said. The tendency for AI models to “hallucinate” and contain bias presents serious risks for using AI to replace doctors. Both Color’s Laraki and OpenAI’s Lightcap are adamant that doctors be involved in any clinical decisions.
I would probably not personally characterize “‘mundane’ tasks like paperwork and … note-taking” as “curing cancer”. Maybe an oncologist could use some code I developed too; even if it helped them, I wouldn’t be stealing valor from them on the curing-cancer part of their job.
Even fully giving it the benefit of the doubt that it works great, and improves patient outcomes significantly, this is medical back-office software. It is not super-intelligence.
It would not even matter if it were “super-intelligence”, whatever that means, because “intelligence” is not how you do medical care or medical research. It’s called “lab work” not “lab think”.
To put a fine point on it: biomedical research fundamentally cannot be done entirely by reading papers or processing existing information. It cannot even be done by testing drugs in computer simulations.
Biological systems are enormously complex, and medical research on new therapies inherently requires careful, repeated empirical testing to validate the correspondence of existing research with reality. Not “an experiment”, but a series of coordinated experiments that all test the same theoretical model. The data (which, in an LLM context, is “training data”) might just be wrong; it may not reflect reality, and the only way to tell is to continuously verify it against reality.
Previous observations can be tainted by methodological errors, by data fraud, and by operational mistakes by practitioners. If there were a way to do verifiable development of new disease therapies without the extremely expensive ladder going from cell cultures to animal models to human trials, we would already be doing it, and “AI” would just be an improvement to efficiency of that process. But there is no way to do that and nothing about the technologies involved in LLMs is going to change that fact.
Knowing Things
The practice of science — indeed any practice of the collection of meaningful information — must be done by intentionally and carefully selecting inclusion criteria, methodically and repeatedly curating our data, building a model that operates according to rules we understand and can verify, and verifying the data itself with repeated tests against nature. We cannot just hoover up whatever information happens to be conveniently available with no human intervention and hope it resolves to a correct model of reality by accident. We need to look where the keys are, not where the light is.
Piling up more and more information in a haphazard and increasingly precarious pile will not allow us to climb to the top of that pile, all the way to heaven, so that we can attack and dethrone God.
Eventually, we’ll just run out of disk space, and then lose the database file when the family gets a new computer anyway.
Acknowledgments
Thank you to my patrons who are supporting my writing on this blog. Special thanks also to Ben Chatterton for a brief pre-publication review; any errors remain my own. If you like what you’ve read here and you’d like to read more of it, or you’d like to support my various open-source endeavors, you can support my work as a sponsor! Special thanks also to Itamar Turner-Trauring and Thomas Grainger for pre-publication feedback on this article; any errors of course remain my own.
March 31, 2025
Ari Lamstein
censusdis v1.4.0 is now on PyPI
I recently contributed a new module to the censusdis package. This resulted in a new version of the package being pushed to PyPI. You can install it like this:
$ pip install censusdis -U #Verify that the installed version is 1.4.0 $ pip freeze | grep censusdis censusdis==1.4.0
The module I created is called multiyear. It is very similar to the utils module I created for my hometown_analysis project. This notebook demonstrates how to use the module. You can view the PR for the module here.
This PR caused me to grow as a Python programmer. Since many of my readers are looking to improve their technical skills, I thought to write down some of my lessons learned.
Python Files, Modules vs. Packages
The vocabulary around files, modules and packages in Python is confusing. This PR is when the terms finally clicked:
- A module is just a normal file with Python code (really). I am not sure why Python invented a new word for this. My best guess is to acknowledge that you can selectively import symbols from a module. This is different than C++ (the first language I programmed in professionally), where
#include <file>imports all of the target file. - A package is just a directory that contains Python modules. The best practice appears to be putting a file named
__init__.pyin the directory to denote that it’s a package. Although the file can be empty and is not strictly necessary (link). This also seems like an odd design decision.
One nice thing about this system is that it allows a package to span multiple (sub)directories. In R, all the code for a package must be in a single directory. I always felt that this limited the complexity of packages in R. It’s nice that Python doesn’t have that limitation.
Dependency Management
Python programmers like to talk about “dependency management hell.” This project gave me my first taste of that.
The initial version of the multiyear module used plotly to make the output of graph_multiyear interactive. I used it to do exploratory data analysis in Jupyter notebooks. However, when I tried to share those notebooks via github the images didn’t render: apparently Jupyter notebooks in github cannot render Javascript. The solution I stumbled upon is described here and requires the kaleido package.
The issue? Apparently this solution works with kaleido v0.2.0, but not the latest version of kaleido (link). So anyone who wants this functionality will need to install a specific version of kaleido. In Python this is known as “pinning” a dependency.
Technically, I believe you can do this by modifying the project’s pyproject.toml file by hand. But in practice people use tools like uv or poetry to both manage this file and create a “lockfile” which states the exact version of all packages you’re using. In this project I got experience doing this with both uv (which I used for my hometown_analysis repo) and poetry (which censusdis uses).
Linting
At my last job I advocated for having all the data scientists use a Style Guide. At that company we used R, and people were ok giving up some issues of personal taste in order to make collaboration easier. The process of enforcing adherence to a style guide (or running automated checks on code to detect errors) is called “linting”, and it’s a step we did not take.
In my hometown_analysis repo I regularly used black for this. It appears that black is the most widely used code formatter in the Python world. It was my first time using it on a project, and I simply ran it myself prior to checking in code.
The Censusdis repo takes this a step further:
- In addition to running black, it recommends contributors also run flake8 and ruff on their code prior to making a PR. For better or for worse, Python seems to have a lot of tools that do linting. There appears to be some overlap in what they all do, and I can’t speak to the unique differences between them. One thing that surprised me is that at least one of them was particular about the format in which I wrote documentation for my functions.
- It automatically runs all of these tools on each PR using Github Actions (link). If any of the linter tools detects an issue it causes the PR to fail the automated test suite.
Automated Tests
Speaking of tests: I did not feel the need to write them for my utils module for the hometown_analysis project. But censusdis uses pytest and has 99% test coverage (link). So it seemed appropriate to add tests to the multiyear module.
Writing tests is something that I’ve done occasionally throughout my career. Pytest was covered in Matt Harrison’s Professional Python course that I took last year, but I found that I forgot a lot of the material. So I did what most engineers would do: I looked at examples in the codebase and used an LLM to help me.
Type Annotations
I have mixed feelings about Python’s use of Type Annotations.
I began my software engineering career using C++, which is a statically typed language. Every variable in a C++ program must have a type defined at compile time (i.e. before the program executes). Python does not have this requirement, which I initially found freeing. Type annotations, I find, remove a lot of this freedom and also make the code a bit harder to read.
That being said, the censusdis package uses them throughout the codebase, so I added them to my module.
In Professional Python I was taught to run mypy to type check my type annotations. While I believe that my code passed without error, I noticed that the project had a few errors that were not covered in my course. For example:
cli/cli.py:9: error: Skipping analyzing "geopandas": module is installed, but missing library stubs or py.typed marker
It appears that type annotations become more complex when your code uses types defined by third-party libraries (such as Pandas and, in this case, GeoPandas). I researched these errors briefly and created a github issue for them.
Code Review
A major source of learning comes when someone more experienced than you reviews your code. This was one of the main reasons I chose to do this project: Darren (the maintainer of censusdis) is much more experienced than me at building Python packages, and I was interested in his feedback on my module.
Interestingly, his initial feedback was that it would be better if the graph_multiyear function used matplotlib instead of plotly. Not because matplotlib is better than plotly, but because other parts of censusdis already use matplotlib. And there’s value in a package having consistency in terms of which visualization package it uses. This made sense to me, although I do miss the interactive plots that plotly provided!
Conclusion
The book Software Engineering at Google defines software engineering as “programming integrated over time.” The idea is that when code is written for a small project, software engineering best practices aren’t that important. But when code is used over a long period of time, they become essential. This idea stayed with me throughout this project.
-
- The first time I did a multi-year analysis of ACS data was for my Covid Demographics Explorer, which I completed last June. I considered the project a one-off. I wrote a single script to download the data and an app to visualize it.
- For my hometown_analysis project I wanted to do exploratory data analysis of several variables over time. So I wrote a handful of functions to download and visualize multi-year ACS data. I put all the code in a single module and pinned the dependencies. I wrote docstrings for all the functions. I reasoned that if I ever want to do a similar analysis in the future then I could reuse the code.
- When I wanted to make it easier for others to use the code I added it to an existing package. That required being more rigorous about coding style, adding automated tests and type annotations. It also required me to make design decisions that are best for the overall package, even when they conflict with design decisions I made when working on the module independently.
My impression is that a lot of Python programmers (especially data scientists) have never contributed their code to an existing package. If you are given the opportunity, then I recommend giving it a shot. I found that it helped me grow as a Python programmer.
While I have disabled comments on my blog, I welcome hearing from reader. Use this form to contact me.
Real Python
Python's Bytearray: A Mutable Sequence of Bytes
Python’s bytearray is a mutable sequence of bytes that allows you to manipulate binary data efficiently. Unlike immutable bytes, bytearray can be modified in place, making it suitable for tasks requiring frequent updates to byte sequences.
You can create a bytearray using the bytearray() constructor with various arguments or from a string of hexadecimal digits using .fromhex(). This tutorial explores creating, modifying, and using bytearray objects in Python.
By the end of this tutorial, you’ll understand that:
- A
bytearrayin Python is a mutable sequence of bytes that allows in-place modifications, unlike the immutablebytes. - You create a
bytearrayby using thebytearray()constructor with a non-negative integer, iterable of integers, bytes-like object, or a string with specified encoding. - You can modify a
bytearrayin Python by appending, slicing, or changing individual bytes, thanks to its mutable nature. - Common uses for
bytearrayinclude processing large binary files, working with network protocols, and tasks needing frequent updates to byte sequences.
You’ll dive deeper into each aspect of bytearray, exploring its creation, manipulation, and practical applications in Python programming.
Get Your Code: Click here to download the free sample code that you’ll use to learn about Python’s bytearray data type.
Take the Quiz: Test your knowledge with our interactive “Python's Bytearray” quiz. You’ll receive a score upon completion to help you track your learning progress:
Interactive Quiz
Python's BytearrayIn this quiz, you'll test your understanding of Python's bytearray data type. By working through this quiz, you'll revisit the key concepts and uses of bytearray in Python.
Understanding Python’s bytearray Type
Although Python remains a high-level programming language, it exposes a few specialized data types that let you manipulate binary data directly should you ever need to. These data types can be useful for tasks such as processing custom binary file formats, or working with low-level network protocols requiring precise control over the data.
The three closely related binary sequence types built into the language are:
bytesbytearraymemoryview
While they’re all Python sequences optimized for performance when dealing with binary data, they each have slightly different strengths and use cases.
Note: You’ll take a deep dive into Python’s bytearray in this tutorial. But, if you’d like to learn more about the companion bytes data type, then check out Bytes Objects: Handling Binary Data in Python, which also covers binary data fundamentals.
As both names suggest, bytes and bytearray are sequences of individual byte values, letting you process binary data at the byte level. For example, you may use them to work with plain text data, which typically represents characters as unique byte values, depending on the given character encoding.
Python natively interprets bytes as 8-bit unsigned integers, each representing one of 256 possible values (28) between 0 and 255. But sometimes, you may need to interpret the same bit pattern as a signed integer, for example, when handling digital audio samples that encode a sound wave’s amplitude levels. See the section on signedness in the Python bytes tutorial for more details.
The choice between bytes and bytearray boils down to whether you want read-only access to the underlying bytes or not. Instances of the bytes data type are immutable, meaning each one has a fixed value that you can’t change once the object is created. In contrast, bytearray objects are mutable sequences, allowing you to modify their contents after creation.
While it may seem counterintuitive at first—since many newcomers to Python expect objects to be directly modifiable—immutable objects have several benefits over their mutable counterparts. That’s why types like strings, tuples, and others require reassignment in Python.
The advantages of immutable data types include better memory efficiency due to the ability to cache or reuse objects without unnecessary copying. In Python, immutable objects are inherently hashable, so they can become dictionary keys or set elements. Additionally, relying on immutable objects gives you extra security, data integrity, and thread safety.
That said, if you need a binary sequence that allows for modification, then bytearray is the way to go. Use it when you frequently perform in-place byte operations that involve changing the contents of the sequence, such as appending, inserting, extending, or modifying individual bytes. A scenario where bytearray can be particularly useful includes processing large binary files in chunks or incrementally reading messages from a network buffer.
The third binary sequence type in Python mentioned earlier, memoryview, provides a zero-overhead view into the memory of certain objects. Unlike bytes and bytearray, whose mutability status is fixed, a memoryview can be either mutable or immutable depending on the target object it references. Just like bytes and bytearray, a memoryview may represent a series of single bytes, but at the same time, it can represent a sequence of multi-byte words.
Now that you have a basic understanding of Python’s binary sequence types and where bytearray fits into them, you can explore ways to create and work with bytearray objects in Python.
Creating bytearray Objects in Python
Unlike the immutable bytes data type, whose literal form resembles a string literal prefixed with the letter b—for example, b"GIF89a"—the mutable bytearray has no literal syntax in Python. This distinction is important despite many similarities between both byte-oriented sequences, which you’ll discover in the next section.
The primary way to create new bytearray instances is by explicitly calling the type’s class constructor, sometimes informally known as the bytearray() built-in function. Alternatively, you can create a bytearray from a string of hexadecimal digits. You’ll learn about both methods next.
The bytearray() Constructor
Read the full article at https://realpython.com/python-bytearray/ »
[ Improve Your Python With 🐍 Python Tricks 💌 – Get a short & sweet Python Trick delivered to your inbox every couple of days. >> Click here to learn more and see examples ]
PyBites
Try an AI Speed Run For Your Next Side Project
The Problem
I have for as long as I can remember had a bit of a problem with analysis paralysis and tunnel vision.
If I’m working on a problem and get stuck, I have a tendency to just sit there paging through code trying to understand where to go next. It’s a very unproductive habit and one I’m committed to breaking, because the last thing you want is to lose hours of wall clock time with no progress on your work.
I was talking to my boss about this a few weeks back when I had a crazy idea: “Hey what if I wrote a program that looked for a particular key combo that I’d hit every time I make progress, and if a specified period e.g. 15 or 30 minutes go by with no progress, a loud buzzer gets played to remind me to ask for help, take a break, or just try something different.”
He thought this was a great idea, and suggested that this would be an ideal candidate to try as an “AI speed run”.
This article is a brief exploration of the process I used with some concrete hints on things that helped me make this project a success that you can use in your own coding “speed run” endeavors 
Explain LIke The AI is 5
For purposes of this discussion I used ChatGPT with its GPT4.0 model. There’s nothing magical about that choice, you can use Claude or any other LLM that fits your needs.
Now comes the important part – coming up with the prompt! The first and most important part of building any program is coming to a full and detailed understanding of what you want to build.
Be as descriptive as you can, being sure to include all the most salient aspects of your project.
What does it do? Here’s where detail and specifics are super important. Where does it need to run? In a web browser? Windows? Mac? Linux? These are just examples of the kinds of detail you must include.
The initial prompt I came up with was: “Write a program that will run on Mac, Windows and Linux. The program should listen for a particular key combination, and if it doesn’t receive that combination within a prescribed (configurable) time, it plays a notification sound to the user.”.
Try, Try Again
Building software with a large language model isn’t like rubbing a magic lamp and making a wish, asking for your software to appear.
Instead, it’s more like having a conversation about what you want to build with an artist about something you want them to create for you.
The LLM is almost guaranteed to not produce exactly what you want on the first try. You can find the complete transcript of my conversation with ChatGPT for this project here.
Do take a moment to read through it a bit. Notice that on the first try it didn’t work at all, so I told it that and gave it the exact error. The fix it suggested wasn’t helping, so I did a tiny bit of very basic debugging and found that one of the modules it was suggested (the one for keyboard input) blew up as soon as I ran its import. So I told it that and suggested that the problem was with the other module that played the buzzer sound.
Progress Is A Change In Error Messages
Once we got past all the platform specific library shenanigans, there were structural issues with the code that needed to be addressed. When I ran the code it generated I got this:
UnboundLocalError: cannot access local variable 'watchdog_last_activity' where it is not associated with a valueSo I told it that by feeding the error back in. It then corrected course and generated the first fully working version of the program. Success!
And I don’t know about you, but a detail about this process that still amazes me? This whole conversation took less than an hour from idea to working program! That’s quite something.
Packaging And Polish
When Bob suggested that I should publish my project to the Python package repository I loved the idea, but I’d never done this before. Lately I’ve been using the amazing uv for all things package related. It’s an amazing tool!
So I dug into the documentation and started playing with my pyproject.toml. And if I’m honest? It wasn’t going very well. I kept trying to run uv publish and kept getting what seemed to me like inscrutable metadata errors
At moments like that I try to ask myself one simple question: “Am I following the happy path?” and in this case, the answer was no
When I started this project, I had used the uv init command to set up the project. I began to wonder whether I had set things up wrong, so I pored over the uv docs and one invocation of uv init --package later I had a buildable package that I could publish to pypi!
There was one bit of polish remaining before I felt like I could call this project “done” as a minimum viable product.
Buzzer, Buzzer, Who’s Got the Buzzer?
One of the things I’d struggled with since I first tried to package the program was where to put and how to bundle the sound file for the buzzer.
After trying various unsatisfying and sub-optimal things like asking the user to supply their own and using a command line argument to locate it, one of Bob’s early suggestions came to mind: I really needed to bundle the sound inside the package in such a way that the program could load it at run time.
LLM To The Res-Cue. Again!
One of the things you learn as you start working with large language models is that they act like a really good pair programming buddy. They offer another place to turn when you get stuck. So I asked ChatGPT:
Write a pyproject.toml for a Python package that includes code that loads a sound file from inside the package.
That did the trick! ChatGPT gave me the right pointers to include in my project toml file as well as the Python code to load the included sound file at run time!
Let AI Help You Boldly Go Where You’ve Never Been Before
As you can see from the final code, this program uses cross platform Python modules for sound playback and keyboard input and more importantly uses threads to manage the real time capture of keypresses while keeping track of the time.
I’ve been in this industry for over 30 years, and a recurring theme I’ve been hearing for most of that time is “Threads are hard”. And they are! But there are also cases like this where you can use them simply and reliably where they really make good sense! I know that now, and would feel comforable using them this way in a future project. There’s value in that! Any tool we can use to help us grow and improve our skills is one worth using, and if we take the time to understand the code AI generates for us it’s a good investment in my book!
Conclusions
I’m very grateful to my manager for having suggested that I try building this project as an “AI speed run”. It’s not something that would have occurred to me but in the end analysis it was a great experience from which I learned a lot.
Also? I’m super happy with the resulting tool and use it all the time now to ensure I don’t stay stuck and burn a ton of time making no progress!
You can see the project in its current state on my GitHub. There are lots of ideas I have for extending it in the future including a nice Textual interface and more polish around choosing the key chord and the “buzzer” sound.
Thanks for taking the time to read this. I hope that it inspires you to try your own AI speed run!
Talk Python to Me
#499: BeeWare and the State of Python on Mobile
This episode is all about Beeware, the project that working towards true native apps built on Python, especially for iOS and Android. Russell's been at this for more than a decade, and the progress is now hitting critical mass. We'll talk about the Toga GUI toolkit, building and shipping your apps with Briefcase, the newly official support for iOS and Android in CPython, and so much more. I can't wait to explore how BeeWare opens up the entire mobile ecosystem for Python developers, let's jump right in.<br/> <br/> <strong>Episode sponsors</strong><br/> <br/> <a href='https://talkpython.fm/workbench'>Posit</a><br> <a href='https://talkpython.fm/devopsbook'>Python in Production</a><br> <a href='https://talkpython.fm/training'>Talk Python Courses</a><br/> <br/> <h2 class="links-heading">Links from the show</h2> <div><strong>Anaconda open source team</strong>: <a href="https://www.anaconda.com/our-open-source-commitment?featured_on=talkpython" target="_blank" >anaconda.com</a><br/> <strong>PEP 730 – Adding iOS</strong>: <a href="https://peps.python.org/pep-0730/?featured_on=talkpython" target="_blank" >peps.python.org</a><br/> <strong>PEP 738 – Adding Android</strong>: <a href="https://peps.python.org/pep-0738/?featured_on=talkpython" target="_blank" >peps.python.org</a><br/> <strong>Toga</strong>: <a href="https://beeware.org/project/projects/libraries/toga/?featured_on=talkpython" target="_blank" >beeware.org</a><br/> <strong>Briefcase</strong>: <a href="https://beeware.org/project/projects/tools/briefcase/?featured_on=talkpython" target="_blank" >beeware.org</a><br/> <strong>emscripten</strong>: <a href="https://emscripten.org/?featured_on=talkpython" target="_blank" >emscripten.org</a><br/> <strong>Russell Keith-Magee - Keynote - PyCon 2019</strong>: <a href="https://www.youtube.com/watch?v=ftP5BQh1-YM&ab_channel=PyCon2019" target="_blank" >youtube.com</a><br/> <strong>Watch this episode on YouTube</strong>: <a href="https://www.youtube.com/watch?v=rSiq8iijkKg" target="_blank" >youtube.com</a><br/> <strong>Episode transcripts</strong>: <a href="https://talkpython.fm/episodes/transcript/499/beeware-and-the-state-of-python-on-mobile" target="_blank" >talkpython.fm</a><br/> <br/> <strong>--- Stay in touch with us ---</strong><br/> <strong>Subscribe to Talk Python on YouTube</strong>: <a href="https://talkpython.fm/youtube" target="_blank" >youtube.com</a><br/> <strong>Talk Python on Bluesky</strong>: <a href="https://bsky.app/profile/talkpython.fm" target="_blank" >@talkpython.fm at bsky.app</a><br/> <strong>Talk Python on Mastodon</strong>: <a href="https://fosstodon.org/web/@talkpython" target="_blank" ><i class="fa-brands fa-mastodon"></i>talkpython</a><br/> <strong>Michael on Bluesky</strong>: <a href="https://bsky.app/profile/mkennedy.codes?featured_on=talkpython" target="_blank" >@mkennedy.codes at bsky.app</a><br/> <strong>Michael on Mastodon</strong>: <a href="https://fosstodon.org/web/@mkennedy" target="_blank" ><i class="fa-brands fa-mastodon"></i>mkennedy</a><br/></div>
Python Bytes
#426 Committing to Formatted Markdown
<strong>Topics covered in this episode:</strong><br> <ul> <li><a href="https://github.com/hukkin/mdformat?featured_on=pythonbytes"><strong>mdformat</strong></a></li> <li><strong><a href="https://github.com/tox-dev/pre-commit-uv?featured_on=pythonbytes">pre-commit-uv</a></strong></li> <li><strong>PEP 758 and 781</strong></li> <li><strong><a href="https://github.com/lusingander/serie?featured_on=pythonbytes">Serie</a>: rich git commit graph in your terminal, like magic <img src="https://paper.dropboxstatic.com/static/img/ace/emoji/1f4da.png?version=8.0.0" alt="books" /></strong></li> <li><strong>Extras</strong></li> <li><strong>Joke</strong></li> </ul><a href='https://www.youtube.com/watch?v=-hHtfY8gW_0' style='font-weight: bold;'data-umami-event="Livestream-Past" data-umami-event-episode="426">Watch on YouTube</a><br> <p><strong>About the show</strong></p> <p>Sponsored by <strong>Posit Connect Cloud</strong>: <a href="https://pythonbytes.fm/connect-cloud">pythonbytes.fm/connect-cloud</a></p> <p><strong>Connect with the hosts</strong></p> <ul> <li>Michael: <a href="https://fosstodon.org/@mkennedy"><strong>@mkennedy@fosstodon.org</strong></a> <strong>/</strong> <a href="https://bsky.app/profile/mkennedy.codes?featured_on=pythonbytes"><strong>@mkennedy.codes</strong></a> <strong>(bsky)</strong></li> <li>Brian: <a href="https://fosstodon.org/@brianokken"><strong>@brianokken@fosstodon.org</strong></a> <strong>/</strong> <a href="https://bsky.app/profile/brianokken.bsky.social?featured_on=pythonbytes"><strong>@brianokken.bsky.social</strong></a></li> <li>Show: <a href="https://fosstodon.org/@pythonbytes"><strong>@pythonbytes@fosstodon.org</strong></a> <strong>/</strong> <a href="https://bsky.app/profile/pythonbytes.fm"><strong>@pythonbytes.fm</strong></a> <strong>(bsky)</strong></li> </ul> <p>Join us on YouTube at <a href="https://pythonbytes.fm/stream/live"><strong>pythonbytes.fm/live</strong></a> to be part of the audience. Usually <strong>Monday</strong> at 10am PT. Older video versions available there too.</p> <p>Finally, if you want an artisanal, hand-crafted digest of every week of the show notes in email form? Add your name and email to <a href="https://pythonbytes.fm/friends-of-the-show">our friends of the show list</a>, we'll never share it. </p> <p><strong>Brian #1:</strong> <a href="https://github.com/hukkin/mdformat?featured_on=pythonbytes"><strong>mdformat</strong></a></p> <ul> <li>Suggested by Matthias Schöttle</li> <li><a href="https://pythonbytes.fm/episodes/show/425/if-you-were-a-klingon-programmer">Last episode </a>Michael covered blacken-docs, and I mentioned it’d be nice to have an autoformatter for text markdown.</li> <li>Matthias delivered with suggesting mdformat</li> <li>“Mdformat is an opinionated Markdown formatter that can be used to enforce a consistent style in Markdown files.”</li> <li>A python project that can be run on the command line.</li> <li>Uses a <a href="https://mdformat.readthedocs.io/en/stable/users/style.html?featured_on=pythonbytes">style guide</a> I mostly agree with. <ul> <li>I’m not a huge fan of numbered list items all being “1.”, but that can be turned off with --number, so I’m happy.</li> <li>Converts underlined headings to #, ##, etc. headings.</li> <li>Lots of other sane conventions.</li> <li>The numbering thing is also sane, I just think it also makes the raw markdown hard to read.</li> </ul></li> <li>Has a <a href="https://mdformat.readthedocs.io/en/stable/users/plugins.html?featured_on=pythonbytes">plugin system to format code blocks</a></li> </ul> <p><strong>Michael #2:</strong> <a href="https://github.com/tox-dev/pre-commit-uv?featured_on=pythonbytes">pre-commit-uv</a></p> <ul> <li>via Ben Falk</li> <li>Use uv to create virtual environments and install packages for pre-commit.</li> </ul> <p><strong>Brian #3:</strong> <strong>PEP 758 and 781</strong></p> <ul> <li><a href="https://peps.python.org/pep-0758/?featured_on=pythonbytes">PEP 758 – Allow except and except* expressions without parentheses</a> <ul> <li>accepted</li> </ul></li> <li><a href="https://peps.python.org/pep-0781/?featured_on=pythonbytes">PEP 781 – Make TYPE_CHECKING a built-in constant</a> <ul> <li>draft status</li> </ul></li> <li>Also,<a href="https://peps.python.org/pep-0000/#index-by-category"> PEP Index by Category </a>kinda rocks</li> </ul> <p><strong>Michael #4:</strong> <a href="https://github.com/lusingander/serie?featured_on=pythonbytes">Serie</a>: rich git commit graph in your terminal, like magic <img src="https://paper.dropboxstatic.com/static/img/ace/emoji/1f4da.png?version=8.0.0" alt="books" /></p> <ul> <li>While some users prefer to use Git via CLI, they often rely on a GUI or feature-rich TUI to view commit logs. </li> <li>Others may find git log --graph sufficient.</li> <li><strong>Goals</strong> <ul> <li>Provide a rich git log --graph experience in the terminal.</li> <li>Offer commit graph-centric browsing of Git repositories.</li> </ul></li> </ul> <p><img src="https://github.com/lusingander/serie/raw/master/img/demo.gif" alt="" /></p> <p><strong>Extras</strong> </p> <p>Michael:</p> <ul> <li><a href="https://mkennedy.codes/posts/sunsetting-search/?featured_on=pythonbytes">Sunsetting Search</a>? (<a href="https://www.startpage.com/?featured_on=pythonbytes">Startpage</a>)</li> <li><a href="https://fosstodon.org/@RhetTbull/114237153385659674">Ruff in or out</a>?</li> </ul> <p><strong>Joke:</strong> <a href="https://x.com/PR0GRAMMERHUM0R/status/1902299037652447410?featured_on=pythonbytes">Wishing for wishes</a></p>
Armin Ronacher
I'm Leaving Sentry
Every ending marks a new beginning, and today, is the beginning of a new chapter for me. Ten years ago I took a leap into the unknown, today I take another. After a decade of working on Sentry I move on to start something new.
Sentry has been more than just a job, it has been a defining part of my life. A place where I've poured my energy, my ideas, my heart. It has shaped me, just as I've shaped it. And now, as I step away, I do so with immense gratitude, a deep sense of pride, and a heart full of memories.
From A Chance Encounter
I've known David, Sentry's co-founder (alongside Chris), long before I was ever officially part of the team as our paths first crossed on IRC in the Django community. Even my first commit to Sentry predates me officially working there by a few years. Back in 2013, over conversations in the middle of Russia — at a conference that, incidentally, also led to me meeting my wife — we toyed with the idea of starting a company together. That exact plan didn't materialize, but the seeds of collaboration had been planted.
Conversations continued, and by late 2014, the opportunity to help transform Sentry (which already showed product market fit) into a much bigger company was simply too good to pass up. I never could have imagined just how much that decision would shape the next decade of my life.
To A Decade of Experiences
For me, Sentry's growth has been nothing short of extraordinary. At first, I thought reaching 30 employees would be our ceiling. Then we surpassed that, and the milestones just kept coming — reaching a unicorn valuation was something I once thought was impossible. While we may have stumbled at times, we've also learned immensely throughout this time.
I'm grateful for all the things I got to experience and there never was a dull moment. From representing Sentry at conferences, opening an engineering office in Vienna, growing teams, helping employees, assisting our licensing efforts and leading our internal platform teams. Every step and achievement drove me.
Yet for me, the excitement and satisfaction of being so close to the founding of a company, yet not quite a founder, has only intensified my desire to see the rest of it.
A Hard Goodbye
Walking away from something you love is never easy and leaving Sentry is hard. Really hard. Sentry has been woven into the very fabric of my adult life. Working on it hasn't just spanned any random decade; it perfectly overlapped with marrying my wonderful wife, and growing our family from zero to three kids.
And will it go away entirely? The office is right around the corner afterall. From now on, every morning, when I will grab my coffee, I will walk past it. The idea of no longer being part of the daily decisions, the debates, the momentum — it feels surreal. That sense of belonging to a passionate team, wrestling with tough decisions, chasing big wins, fighting fires together, sometimes venting about our missteps and discussing absurd and ridiculous trivia became part of my identity.
There are so many bright individuals at Sentry, and I'm incredibly proud of what we have built together. Not just from an engineering point of view, but also product, marketing and upholding our core values. We developed SDKs that support a wide array of platforms from Python to JavaScript to Swift to C++, lately expanding to game consoles. We stayed true to our Open Source principles, even when other options were available. For example, when we needed an Open Source PDB implementation for analyzing Windows crashes but couldn't find a suitable solution, we contributed to a promising Rust crate instead of relying on Windows VMs and Microsoft's dbghelp. When we started, our ingestion system handled a few thousand requests per second — now it handles well over a million.
While building an SDK may seem straightforward, maintaining and updating them to remain best-in-class over the years requires immense dedication. It takes determination to build something that works out of the box with little configuration. A lot of clever engineering and a lot of deliberate tradeoffs went into the product to arrive where it is. And ten years later, is a multi-product company. What started with just crashes, now you can send traces, profiles, sessions, replays and more.
We also stuck to our values. I'm pleased that we ran experiments with licensing despite all the push back we got over the years. We might not have found the right solution yet, but we pushed the conversation. The same goes for our commitment to funding of dependencies.
And Heartfelt Thank You
I feel an enormous amount of gratitude for those last ten years. There are so many people I owe thanks to. I owe eternal thanks to David Cramer and Chris Jennings for the opportunity and trust they placed in me. To Ben Vinegar for his unwavering guidance and support. To Dan Levine, for investing in us and believing in our vision. To Daniel Griesser, for being an exceptional first hire in Vienna, and shepherding our office there and growing it to 50 people. To Vlad Cretu, for bringing structure to our chaos over the years. To Milin Desai for taking the helm and growing us.
And most of all, to my wonderful wife, Maria — who has stood beside me through every challenge, who has supported me when the road was uncertain, and who has always encouraged me to forge my own path.
To everyone at Sentry, past and present — thank you. For the trust, the lessons, the late nights, the victories. For making Sentry what it is today.
Quo eo?
I'm fully aware it's a gamble to believe my next venture will find the same success as Sentry. The reality is that startups that achieve the kind of scale and impact Sentry has are incredibly rare. There's a measure of hubris in assuming lightning strikes twice, and as humbling as that realization is, it also makes me that much more determined. The creative spark that fueled me at Sentry isn't dimming. Not at all in fact: it burns brighter fueld by the feeling that I can explore new things, beckoning me. There's more for me to explore, and I'm ready to channel all that energy into a new venture.
Today, I stand in an open field, my backpack filled with experiences and a renewed sense of purpose. That's because the world has changed a lot in the past decade, and so have I. What drives me now is different from what drove me before, and I want my work to reflect that evolution.
At my core, I'm still inspired by the same passion — seeing others find value in what I create, but my perspective has expanded. While I still take great joy in building things that help developers, I want to broaden my reach. I may not stray far from familiar territory, but I want to build something that speaks to more people, something that, hopefully, even my children will find meaningful.
Watch this space, as they say.
March 29, 2025
Ned Batchelder
Human sorting improved
When sorting strings, you’d often like the order to make sense to a person. That means numbers need to be treated numerically even if they are in a larger string.
For example, sorting Python versions with the default sort() would give you:
Python 3.10
Python 3.11
Python 3.9
when you want it to be:
Python 3.9
Python 3.10
Python 3.11
I wrote about this long ago (Human sorting), but have continued to tweak the code and needed to add it to a project recently. Here’s the latest:
import re
def human_key(s: str) -> tuple[list[str | int], str]:
"""Turn a string into a sortable value that works how humans expect.
"z23A" -> (["z", 23, "a"], "z23A")
The original string is appended as a last value to ensure the
key is unique enough so that "x1y" and "x001y" can be distinguished.
"""
def try_int(s: str) -> str | int:
"""If `s` is a number, return an int, else `s` unchanged."""
try:
return int(s)
except ValueError:
return s
return ([try_int(c) for c in re.split(r"(\d+)", s.casefold())], s)
def human_sort(strings: list[str]) -> None:
"""Sort a list of strings how humans expect."""
strings.sort(key=human_key)
The central idea here is to turn a string like "Python 3.9" into the
key ["Python ", 3, ".", 9] so that numeric components will be sorted by
their numeric value. The re.split() function gives us interleaved words and
numbers, and try_int() turns the numbers into actual numbers, giving us sortable
key lists.
There are two improvements from the original:
- The sort is made case-insensitive by using casefold() to lower-case the string.
- The key returned is now a two-element tuple: the first element is the list
of intermixed strings and integers that gives us the ordering we want. The
second element is the original string unchanged to ensure that unique strings
will always result in distinct keys. Without it,
"x1y"and"x001Y"would both produce the same key. This solves a problem that actually happened when sorting the items of a dictionary.# Without the tuple: different strings, same key!!
human_key("x1y") -> ["x", 1, "y"]
human_key("x001Y") -> ["x", 1, "y"]
# With the tuple: different strings, different keys.
human_key("x1y") -> (["x", 1, "y"], "x1y")
human_key("x001Y") -> (["x", 1, "y"], "x001Y")
If you are interested, there are many different ways to split the string into the word/number mix. The comments on the old post have many alternatives, and there are certainly more.
This still makes some assumptions about what is wanted, and doesn’t cover all possible options (floats? negative/positive? full file paths?). For those, you probably want the full-featured natsort (natural sort) package.
Python GUIs
PyQt6 Toolbars & Menus — QAction — Defining toolbars, menus, and keyboard shortcuts with QAction
Next, we'll look at some of the common user interface elements you've probably seen in many other applications — toolbars and menus. We'll also explore the neat system Qt provides for minimizing the duplication between different UI areas — QAction.
Basic App
We'll start this tutorial with a simple skeleton application, which we can customize. Save the following code in a file named app.py -- this code all the imports you'll need for the later steps:
from PyQt6.QtCore import QSize, Qt
from PyQt6.QtGui import QAction, QIcon, QKeySequence
from PyQt6.QtWidgets import (
QApplication,
QCheckBox,
QLabel,
QMainWindow,
QStatusBar,
QToolBar,
)
class MainWindow(QMainWindow):
def __init__(self):
super().__init__()
self.setWindowTitle("My App")
app = QApplication([])
window = MainWindow()
window.show()
app.exec()
This file contains the imports and the basic code that you'll use to complete the examples in this tutorial.
If you're migrating to PyQt6 from PyQt5, notice that QAction is now available via the QtGui module.
Toolbars
One of the most commonly seen user interface elements is the toolbar. Toolbars are bars of icons and/or text used to perform common tasks within an application, for which access via a menu would be cumbersome. They are one of the most common UI features seen in many applications. While some complex applications, particularly in the Microsoft Office suite, have migrated to contextual 'ribbon' interfaces, the standard toolbar is usually sufficient for the majority of applications you will create.
![]() Standard GUI elements
Standard GUI elements
Adding a Toolbar
Let's start by adding a toolbar to our application.
In Qt, toolbars are created from the QToolBar class. To start, you create an instance of the class and then call addToolbar on the QMainWindow. Passing a string in as the first argument to QToolBar sets the toolbar's name, which will be used to identify the toolbar in the UI:
class MainWindow(QMainWindow):
def __init__(self):
super().__init__()
self.setWindowTitle("My App")
label = QLabel("Hello!")
label.setAlignment(Qt.AlignmentFlag.AlignCenter)
self.setCentralWidget(label)
toolbar = QToolBar("My main toolbar")
self.addToolBar(toolbar)
Run it! You'll see a thin grey bar at the top of the window. This is your toolbar. Right-click the name to trigger a context menu and toggle the bar off.
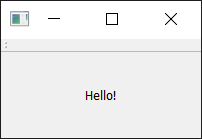 A window with a toolbar.
A window with a toolbar.
How can I get my toolbar back? Unfortunately, once you remove a toolbar, there is now no place to right-click to re-add it. So, as a general rule, you want to either keep one toolbar un-removeable, or provide an alternative interface in the menus to turn toolbars on and off.
We should make the toolbar a bit more interesting. We could just add a QButton widget, but there is a better approach in Qt that gets you some additional features — and that is via QAction. QAction is a class that provides a way to describe abstract user interfaces. What this means in English is that you can define multiple interface elements within a single object, unified by the effect that interacting with that element has.
For example, it is common to have functions that are represented in the toolbar but also the menu — think of something like Edit->Cut, which is present both in the Edit menu but also on the toolbar as a pair of scissors, and also through the keyboard shortcut Ctrl-X (Cmd-X on Mac).
Without QAction, you would have to define this in multiple places. But with QAction you can define a single QAction, defining the triggered action, and then add this action to both the menu and the toolbar. Each QAction has names, status messages, icons, and signals that you can connect to (and much more).
In the code below, you can see this first QAction added:
class MainWindow(QMainWindow):
def __init__(self):
super().__init__()
self.setWindowTitle("My App")
label = QLabel("Hello!")
label.setAlignment(Qt.AlignmentFlag.AlignCenter)
self.setCentralWidget(label)
toolbar = QToolBar("My main toolbar")
self.addToolBar(toolbar)
button_action = QAction("Your button", self)
button_action.setStatusTip("This is your button")
button_action.triggered.connect(self.toolbar_button_clicked)
toolbar.addAction(button_action)
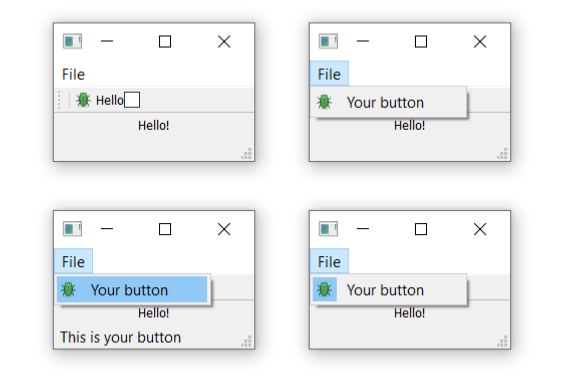
def toolbar_button_clicked(self, s):
print("click", s)
To start with, we create the function that will accept the signal from the QAction so we can see if it is working. Next, we define the QAction itself. When creating the instance, we can pass a label for the action and/or an icon. You must also pass in any QObject to act as the parent for the action — here we're passing self as a reference to our main window. Strangely, for QAction the parent element is passed in as the final argument.
Next, we can opt to set a status tip — this text will be displayed on the status bar once we have one. Finally, we connect the triggered signal to the custom function. This signal will fire whenever the QAction is triggered (or activated).
Run it! You should see your button with the label that you have defined. Click on it, and then our custom method will print "click" and the status of the button.
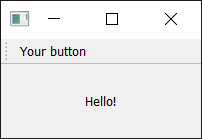 Toolbar showing our
Toolbar showing our QAction button.
Why is the signal always false? The signal passed indicates whether the button is checked, and since our button is not checkable — just clickable — it is always false. We'll show how to make it checkable shortly.
Next, we can add a status bar.
We create a status bar object by calling QStatusBar to get a new status bar object and then passing this into setStatusBar. Since we don't need to change the status bar settings, we can also just pass it in as we create it, in a single line:
class MainWindow(QMainWindow):
def __init__(self):
super().__init__()
self.setWindowTitle("My App")
label = QLabel("Hello!")
label.setAlignment(Qt.AlignmentFlag.AlignCenter)
self.setCentralWidget(label)
toolbar = QToolBar("My main toolbar")
self.addToolBar(toolbar)
button_action = QAction("Your button", self)
button_action.setStatusTip("This is your button")
button_action.triggered.connect(self.toolbar_button_clicked)
toolbar.addAction(button_action)
self.setStatusBar(QStatusBar(self))
def toolbar_button_clicked(self, s):
print("click", s)
Run it! Hover your mouse over the toolbar button, and you will see the status text in the status bar.
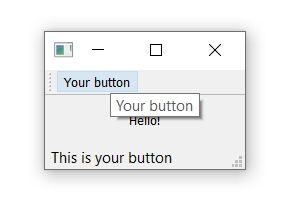 Status bar text updated as we hover over the action.
Status bar text updated as we hover over the action.
Next, we're going to turn our QAction toggleable — so clicking will turn it on, and clicking again will turn it off. To do this, we simply call setCheckable(True) on the QAction object:
class MainWindow(QMainWindow):
def __init__(self):
super().__init__()
self.setWindowTitle("My App")
label = QLabel("Hello!")
label.setAlignment(Qt.AlignmentFlag.AlignCenter)
self.setCentralWidget(label)
toolbar = QToolBar("My main toolbar")
self.addToolBar(toolbar)
button_action = QAction("Your button", self)
button_action.setStatusTip("This is your button")
button_action.triggered.connect(self.toolbar_button_clicked)
button_action.setCheckable(True)
toolbar.addAction(button_action)
self.setStatusBar(QStatusBar(self))
def toolbar_button_clicked(self, s):
print("click", s)
Run it! Click on the button to see it toggle from checked to unchecked state. Note that the custom slot method we create now alternates outputting True and False.
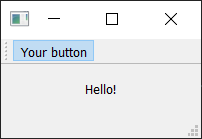 The toolbar button toggled on.
The toolbar button toggled on.
There is also a toggled signal, which only emits a signal when the button is toggled. But the effect is identical, so it is mostly pointless.
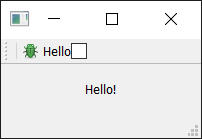
Things look pretty shabby right now — so let's add an icon to our button. For this, I recommend you download the fugue icon set by designer Yusuke Kamiyamane. It's a great set of beautiful 16x16 icons that can give your apps a nice professional look. It is freely available with only attribution required when you distribute your application — although I am sure the designer would appreciate some cash too if you have some spare.
![]() Fugue Icon Set — Yusuke Kamiyamane
Fugue Icon Set — Yusuke Kamiyamane
Select an image from the set (in the examples here, I've selected the file bug.png) and copy it into the same folder as your source code.
We can create a QIcon object by passing the file name to the class, e.g. QIcon("bug.png") -- if you place the file in another folder, you will need a full relative or absolute path to it.
Finally, to add the icon to the QAction (and therefore the button), we simply pass it in as the first argument when creating the QAction.
You also need to let the toolbar know how large your icons are. Otherwise, your icon will be surrounded by a lot of padding. You can do this by calling setIconSize() with a QSize object:
class MainWindow(QMainWindow):
def __init__(self):
super().__init__()
self.setWindowTitle("My App")
label = QLabel("Hello!")
label.setAlignment(Qt.AlignmentFlag.AlignCenter)
self.setCentralWidget(label)
toolbar = QToolBar("My main toolbar")
toolbar.setIconSize(QSize(16, 16))
self.addToolBar(toolbar)
button_action = QAction(QIcon("bug.png"), "Your button", self)
button_action.setStatusTip("This is your button")
button_action.triggered.connect(self.toolbar_button_clicked)
button_action.setCheckable(True)
toolbar.addAction(button_action)
self.setStatusBar(QStatusBar(self))
def toolbar_button_clicked(self, s):
print("click", s)
Run it! The QAction is now represented by an icon. Everything should work exactly as it did before.
![]() Our action button with an icon.
Our action button with an icon.
Note that Qt uses your operating system's default settings to determine whether to show an icon, text, or an icon and text in the toolbar. But you can override this by using setToolButtonStyle(). This slot accepts any of the following flags from the Qt namespace:
| Flag | Behavior |
|---|---|
Qt.ToolButtonStyle.ToolButtonIconOnly |
Icon only, no text |
Qt.ToolButtonStyle.ToolButtonTextOnly |
Text only, no icon |
Qt.ToolButtonStyle.ToolButtonTextBesideIcon |
Icon and text, with text beside the icon |
Qt.ToolButtonStyle.ToolButtonTextUnderIcon |
Icon and text, with text under the icon |
Qt.ToolButtonStyle.ToolButtonFollowStyle |
Follow the host desktop style |
The default value is Qt.ToolButtonStyle.ToolButtonFollowStyle, meaning that your application will default to following the standard/global setting for the desktop on which the application runs. This is generally recommended to make your application feel as native as possible.
Finally, we can add a few more bits and bobs to the toolbar. We'll add a second button and a checkbox widget. As mentioned, you can literally put any widget in here, so feel free to go crazy:
from PyQt6.QtCore import QSize, Qt
from PyQt6.QtGui import QAction, QIcon
from PyQt6.QtWidgets import (
QApplication,
QCheckBox,
QLabel,
QMainWindow,
QStatusBar,
QToolBar,
)
class MainWindow(QMainWindow):
def __init__(self):
super().__init__()
self.setWindowTitle("My App")
label = QLabel("Hello!")
label.setAlignment(Qt.AlignmentFlag.AlignCenter)
self.setCentralWidget(label)
toolbar = QToolBar("My main toolbar")
toolbar.setIconSize(QSize(16, 16))
self.addToolBar(toolbar)
button_action = QAction(QIcon("bug.png"), "&Your button", self)
button_action.setStatusTip("This is your button")
button_action.triggered.connect(self.toolbar_button_clicked)
button_action.setCheckable(True)
toolbar.addAction(button_action)
toolbar.addSeparator()
button_action2 = QAction(QIcon("bug.png"), "Your &button2", self)
button_action2.setStatusTip("This is your button2")
button_action2.triggered.connect(self.toolbar_button_clicked)
button_action2.setCheckable(True)
toolbar.addAction(button_action2)
toolbar.addWidget(QLabel("Hello"))
toolbar.addWidget(QCheckBox())
self.setStatusBar(QStatusBar(self))
def toolbar_button_clicked(self, s):
print("click", s)
app = QApplication([])
window = MainWindow()
window.show()
app.exec()
Run it! Now you see multiple buttons and a checkbox.
 Toolbar with an action and two widgets.
Toolbar with an action and two widgets.
Menus
Menus are another standard component of UIs. Typically, they are at the top of the window or the top of a screen on macOS. They allow you to access all standard application functions. A few standard menus exist — for example File, Edit, Help. Menus can be nested to create hierarchical trees of functions, and they often support and display keyboard shortcuts for fast access to their functions.
 Standard GUI elements - Menus
Standard GUI elements - Menus
Adding a Menu
To create a menu, we create a menubar we call menuBar() on the QMainWindow. We add a menu to our menu bar by calling addMenu(), passing in the name of the menu. I've called it '&File'. The ampersand defines a quick key to jump to this menu when pressing Alt.
This won't be visible on macOS. Note that this is different from a keyboard shortcut — we'll cover that shortly.
This is where the power of actions comes into play. We can reuse the already existing QAction to add the same function to the menu. To add an action, you call addAction() passing in one of our defined actions:
class MainWindow(QMainWindow):
def __init__(self):
super().__init__()
self.setWindowTitle("My App")
label = QLabel("Hello!")
label.setAlignment(Qt.AlignmentFlag.AlignCenter)
self.setCentralWidget(label)
toolbar = QToolBar("My main toolbar")
toolbar.setIconSize(QSize(16, 16))
self.addToolBar(toolbar)
button_action = QAction(QIcon("bug.png"), "&Your button", self)
button_action.setStatusTip("This is your button")
button_action.triggered.connect(self.toolbar_button_clicked)
button_action.setCheckable(True)
toolbar.addAction(button_action)
toolbar.addSeparator()
button_action2 = QAction(QIcon("bug.png"), "Your &button2", self)
button_action2.setStatusTip("This is your button2")
button_action2.triggered.connect(self.toolbar_button_clicked)
button_action2.setCheckable(True)
toolbar.addAction(button_action2)
toolbar.addWidget(QLabel("Hello"))
toolbar.addWidget(QCheckBox())
self.setStatusBar(QStatusBar(self))
menu = self.menuBar()
file_menu = menu.addMenu("&File")
file_menu.addAction(button_action)
def toolbar_button_clicked(self, s):
print("click", s)
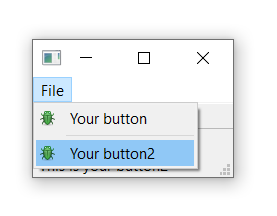
Run it! Click the item in the menu, and you will notice that it is toggleable — it inherits the features of the QAction.
 Menu shown on the window -- on macOS this will be at the top of the screen.
Menu shown on the window -- on macOS this will be at the top of the screen.
Let's add some more things to the menu. Here, we'll add a separator to the menu, which will appear as a horizontal line in the menu, and then add the second QAction we created:
class MainWindow(QMainWindow):
def __init__(self):
super().__init__()
self.setWindowTitle("My App")
label = QLabel("Hello!")
label.setAlignment(Qt.AlignmentFlag.AlignCenter)
self.setCentralWidget(label)
toolbar = QToolBar("My main toolbar")
toolbar.setIconSize(QSize(16, 16))
self.addToolBar(toolbar)
button_action = QAction(QIcon("bug.png"), "&Your button", self)
button_action.setStatusTip("This is your button")
button_action.triggered.connect(self.toolbar_button_clicked)
button_action.setCheckable(True)
toolbar.addAction(button_action)
toolbar.addSeparator()
button_action2 = QAction(QIcon("bug.png"), "Your &button2", self)
button_action2.setStatusTip("This is your button2")
button_action2.triggered.connect(self.toolbar_button_clicked)
button_action2.setCheckable(True)
toolbar.addAction(button_action2)
toolbar.addWidget(QLabel("Hello"))
toolbar.addWidget(QCheckBox())
self.setStatusBar(QStatusBar(self))
menu = self.menuBar()
file_menu = menu.addMenu("&File")
file_menu.addAction(button_action)
file_menu.addSeparator()
file_menu.addAction(button_action2)
def toolbar_button_clicked(self, s):
print("click", s)
Run it! You should see two menu items with a line between them.
 Our actions showing in the menu.
Our actions showing in the menu.
You can also use ampersand to add accelerator keys to the menu to allow a single key to be used to jump to a menu item when it is open. Again this doesn't work on macOS.
To add a submenu, you simply create a new menu by calling addMenu() on the parent menu. You can then add actions to it as usual. For example:
class MainWindow(QMainWindow):
def __init__(self):
super().__init__()
self.setWindowTitle("My App")
label = QLabel("Hello!")
label.setAlignment(Qt.AlignmentFlag.AlignCenter)
self.setCentralWidget(label)
toolbar = QToolBar("My main toolbar")
toolbar.setIconSize(QSize(16, 16))
self.addToolBar(toolbar)
button_action = QAction(QIcon("bug.png"), "&Your button", self)
button_action.setStatusTip("This is your button")
button_action.triggered.connect(self.toolbar_button_clicked)
button_action.setCheckable(True)
toolbar.addAction(button_action)
toolbar.addSeparator()
button_action2 = QAction(QIcon("bug.png"), "Your &button2", self)
button_action2.setStatusTip("This is your button2")
button_action2.triggered.connect(self.toolbar_button_clicked)
button_action2.setCheckable(True)
toolbar.addAction(button_action2)
toolbar.addWidget(QLabel("Hello"))
toolbar.addWidget(QCheckBox())
self.setStatusBar(QStatusBar(self))
menu = self.menuBar()
file_menu = menu.addMenu("&File")
file_menu.addAction(button_action)
file_menu.addSeparator()
file_submenu = file_menu.addMenu("Submenu")
file_submenu.addAction(button_action2)
def toolbar_button_clicked(self, s):
print("click", s)
Run it! You will see a nested menu in the File menu.
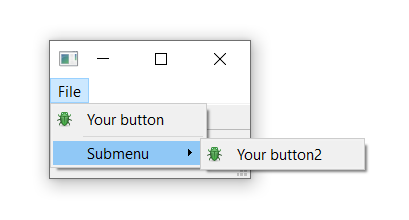 Submenu nested in the File menu.
Submenu nested in the File menu.
Finally, we'll add a keyboard shortcut to the QAction. You define a keyboard shortcut by passing setKeySequence() and passing in the key sequence. Any defined key sequences will appear in the menu.
Note that the keyboard shortcut is associated with the QAction and will still work whether or not the QAction is added to a menu or a toolbar.
Key sequences can be defined in multiple ways - either by passing as text, using key names from the Qt namespace, or using the defined key sequences from the Qt namespace. Use the latter wherever you can to ensure compliance with the operating system standards.
The completed code, showing the toolbar buttons and menus, is shown below:
class MainWindow(QMainWindow):
def __init__(self):
super().__init__()
self.setWindowTitle("My App")
label = QLabel("Hello!")
# The `Qt` namespace has a lot of attributes to customize
# widgets. See: http://doc.qt.io/qt-6/qt.html
label.setAlignment(Qt.AlignmentFlag.AlignCenter)
# Set the central widget of the Window. Widget will expand
# to take up all the space in the window by default.
self.setCentralWidget(label)
toolbar = QToolBar("My main toolbar")
toolbar.setIconSize(QSize(16, 16))
self.addToolBar(toolbar)
button_action = QAction(QIcon("bug.png"), "&Your button", self)
button_action.setStatusTip("This is your button")
button_action.triggered.connect(self.toolbar_button_clicked)
button_action.setCheckable(True)
# You can enter keyboard shortcuts using key names (e.g. Ctrl+p)
# Qt.namespace identifiers (e.g. Qt.CTRL + Qt.Key_P)
# or system agnostic identifiers (e.g. QKeySequence.Print)
button_action.setShortcut(QKeySequence("Ctrl+p"))
toolbar.addAction(button_action)
toolbar.addSeparator()
button_action2 = QAction(QIcon("bug.png"), "Your &button2", self)
button_action2.setStatusTip("This is your button2")
button_action2.triggered.connect(self.toolbar_button_clicked)
button_action2.setCheckable(True)
toolbar.addAction(button_action2)
toolbar.addWidget(QLabel("Hello"))
toolbar.addWidget(QCheckBox())
self.setStatusBar(QStatusBar(self))
menu = self.menuBar()
file_menu = menu.addMenu("&File")
file_menu.addAction(button_action)
file_menu.addSeparator()
file_submenu = file_menu.addMenu("Submenu")
file_submenu.addAction(button_action2)
def toolbar_button_clicked(self, s):
print("click", s)
Experiment with building your own menus using QAction and QMenu.
March 28, 2025
Robin Wilson
Learning resources for GIS in Python with cloud-native geospatial, PostGIS and more
I recently gave a careers talk to students at Solent University, and through that I got to know a MSc student there who had previous GIS experience and was now doing a Data Analytics and AI MSc course. Her GIS experience was mostly in the ESRI stack (ArcGIS and related tools) and she was keen to learn other tools and how to combine her new Python and data knowledge with her previous GIS knowledge. I wrote her a long email with links to loads of resources and, with her permission, I’m publishing it here as it may be useful to others. The general focus is on the tools I use, which are mostly Python-focused, but also on becoming familiar with a range of tools rather than using tools from just one ecosystem (like ESRI). I hope it is useful to you.
Tools to investigate:
-
GDAL
GDAL is a library that consists of two parts GDAL and OGR. It provides ways to read and write geospatial data formats like shapefile, geopackage, GeoJSON, GeoTIFF etc – both raster (GDAL) and vector (OGR). It has a load of command-line tools like gdal_translate, ogr2ogr, gdalwarp and so on. These are extremely useful for converting between formats, importing data to databases, doing basic processing etc. It will be very useful for you to become familiar with the GDAL command-line tools. It comes with a Python interface which is a bit of a pain to use, and there are nicer libraries that are easier for using GDAL functionality from Python. A good tutorial for the command-line tools is at https://courses.spatialthoughts.com/gdal-tools.html -
Command line tools in general
Getting familiar with running things from the command-line (Command Prompt on Windows) is very useful. On Windows I suggest installing ‘Windows Terminal’ (https://apps.microsoft.com/detail/9n0dx20hk701?hl=en-GB&gl=GB) and using that – but make sure you select standard command prompt not Powershell when you open a terminal using it. -
Git
There’s a good tutorial at https://swcarpentry.github.io/git-novice/ -
qgis2web
This is a plugin for QGIS that will export a QGIS project to a standalone web map, with the styling/visualisation as close to the original QGIS project as they can manage. It’s very useful for exporting maps to share easily. There’s a tutorial at https://www.qgistutorials.com/en/docs/web_mapping_with_qgis2web.html and the main page is at https://plugins.qgis.org/plugins/qgis2web/
Python libraries to investigate:
- GeoPandas – like pandas but including geometry columns for geospatial information. Try the geopandas
explore()method, which will do an automatic webmap of a GeoPandas GeoDataFrame (like you did manually with Folium, but automatically) - rasterio – a nice wrapper around GDAL functionality that lets you easily load/manipulate/save raster geospatial data
- fiona – a similar wrapper for vector data in GDAL/OGR
- shapely – a library for representing vector geometries in Python – used by fiona, GeoPandas etc
- rasterstats – a library for doing ‘zonal statistics’ – ie. getting raster values within a polygon, at a point etc
Cloud Native Geospatial
There’s a good ‘zine’ that explains the basics behind cloud-native geospatial – see https://zines.developmentseed.org/zines/cloud-native/. Understanding the basics of the topics in there would be good. There are loads of good tutorials online for using STAC catalogues, COG files and so on. See https://planetarycomputer.microsoft.com/docs/quickstarts/reading-stac/ and https://planetarycomputer.microsoft.com/docs/tutorials/cloudless-mosaic-sentinel2/ and https://github.com/microsoft/PlanetaryComputerExamples/blob/main/tutorials/surface_analysis.ipynb
My Blog
You can subscribe via email on the left-hand side at the bottom of the sidebar
Relevant posts:
- https://blog.rtwilson.com/searching-an-aerial-photo-with-text-queries-a-demo-and-how-it-works/
- https://blog.rtwilson.com/simple-segmentation-of-geospatial-images/
- https://blog.rtwilson.com/whats-the-largest-building-in-southampton-find-out-with-5-lines-of-code/
- https://blog.rtwilson.com/simple-self-hosted-openstreetmap-routing-using-valhalla-and-docker/
- https://blog.rtwilson.com/how-to-speed-up-appending-to-postgis-tables-with-ogr2ogr/
- https://blog.rtwilson.com/how-to-fix-geopandas-drop_duplicates-on-geometry-column-not-getting-rid-of-all-duplicates/
- https://blog.rtwilson.com/how-to-easily-reload-a-qgis-layer/
- https://blog.rtwilson.com/travel-times-over-time/
Conference talks
These can be a really good way to get a brief intro to a topic, to know where to delve in deeper later. I often put them on and half-listen while I’m doing something else, and then switch to focusing on them fully if they get particularly interesting. There are loads of links here, don’t feel like you have to look at them all!
PostGIS Day conference: https://www.crunchydata.com/blog/postgis-day-2024-summary
Particularly relevant talks:
- https://www.youtube.com/watch?v=O45Zy5zKkm8 – good example of building up a complex SQL query
- https://www.youtube.com/watch?v=mR0WshjWfVY – includes descriptions of on-the-fly Mapbox Vector Tile creation like we use in GPAP
- https://www.youtube.com/watch?v=BsFCVTBzTvY – also includes on-the-fly MVT creation
https://www.youtube.com/watch?v=1KhWJHKuNCY
FOSS4G UK conference last year in Bristol: https://uk.osgeo.org/foss4guk2024/bristol.html
Most relevant talks for you are the following (just the slides):
- https://uk.osgeo.org/foss4guk2024/decks/08-robin-wilson-cloud-native-flood-risk.pdf – see what you think of the large SQL query that I talk through
- https://uk.osgeo.org/foss4guk2024/decks/11-al-graham-overture.pdf
- https://uk.osgeo.org/foss4guk2024/decks/13-alexei-qgis-grid-layout-plugin.pdf
- https://uk.osgeo.org/foss4guk2024/decks/14-matt-travis-overture.pdf
FOSS4G conference YouTube videos: https://www.youtube.com/@FOSS4G/videos – they have a load of ones from 2022 at the top for some reason, but if you scroll down a long way you can find 2023 and 2024 stuff. Actually, better is to use this playlist of talks from the 2023 global conference: https://www.youtube.com/playlist?list=PLqa06jy1NEM2Kna9Gt_LDKZHv1dl4xUoZ
Here’s a few talks that might be particularly interesting/relevant to you, in no particular order
- https://www.youtube.com/watch?v=g7iMO1KmyJE&list=PLqa06jy1NEM2Kna9Gt_LDKZHv1dl4xUoZ&index=47
- https://www.youtube.com/watch?v=QN1CQZ9xq6Y&list=PLqa06jy1NEM2Kna9Gt_LDKZHv1dl4xUoZ&index=49
- https://www.youtube.com/watch?v=uOziWmcn7z0&list=PLqa06jy1NEM2Kna9Gt_LDKZHv1dl4xUoZ&index=53
- https://www.youtube.com/watch?v=jfaizvF5S4I&list=PLqa06jy1NEM2Kna9Gt_LDKZHv1dl4xUoZ&index=56
- https://www.youtube.com/watch?v=gl7LMEPvAmo&list=PLqa06jy1NEM2Kna9Gt_LDKZHv1dl4xUoZ&index=105
- https://www.youtube.com/watch?v=KCfMljtOzWQ&list=PLqa06jy1NEM2Kna9Gt_LDKZHv1dl4xUoZ&index=111
- https://www.youtube.com/watch?v=6ZFjSXAOkss&list=PLqa06jy1NEM2Kna9Gt_LDKZHv1dl4xUoZ&index=137
- https://www.youtube.com/watch?v=oK7QxhAWPTc&list=PLqa06jy1NEM2Kna9Gt_LDKZHv1dl4xUoZ&index=140
- https://www.youtube.com/watch?v=OtsvoR0wo80&list=PLqa06jy1NEM2Kna9Gt_LDKZHv1dl4xUoZ&index=141
- https://www.youtube.com/watch?v=0QMmfGn7btc&list=PLqa06jy1NEM2Kna9Gt_LDKZHv1dl4xUoZ&index=148
- https://www.youtube.com/watch?v=ZBj77BRx-XE&list=PLqa06jy1NEM2Kna9Gt_LDKZHv1dl4xUoZ&index=193
- https://www.youtube.com/watch?v=Y-t5wHq7OrA&list=PLqa06jy1NEM2Kna9Gt_LDKZHv1dl4xUoZ&index=227
- https://www.youtube.com/watch?v=UKbmeFkW8nM&list=PLqa06jy1NEM2Kna9Gt_LDKZHv1dl4xUoZ&index=230
- https://www.youtube.com/watch?v=snGDbX8pG2I&list=PLqa06jy1NEM2Kna9Gt_LDKZHv1dl4xUoZ&index=256
Suggestions for learning projects/tasks
(These are quite closely related to the MSc project that this student might be doing, but are probably useful for people generally)
I know when you’re starting off it is hard to work out what sort of things to do to develop your skills. One thing that is really useful is to become a bit of a ‘tool polyglot’, so you can do the same task in various tools depending on what makes sense in the circumstances.
I’ve listed a couple of tasks below. I’d suggest trying to complete them in a few ways:
- Using QGIS and clicking around in the GUI
- Using Python libraries like geopandas, rasterio and so on
- Using PostGIS
- (Possibly – not essential) Using the QGIS command-line, or model builder or similar
Task 1 – Flood risk
- Download the ‘Flood Zone 2’ flood risk data from https://environment.data.gov.uk/explore/86ec354f-d465-11e4-b09e-f0def148f590?download=true for a particular area (maybe the whole of Southampton?)
- Download OS data on buildings from this page – https://automaticknowledge.org/gb/ – you can download it for a specific local authority area
- Find all buildings at risk of flooding, and provide a count of buildings at risk and a map of buildings at risk (static map or web map)
- Extension task: also provide a total ground area of buildings at risk
Task 2 – Elevation data
(Don’t do this with PostGIS as its raster functionality isn’t great, but you could probably do all of this with GDAL command-line tools if you wanted)
- Download Digital Terrain Model data from https://environment.data.gov.uk/survey – download multiple tiles
- Mosaic the tiles together into one large image file
- Do some basic processing on the DEM data. For example, try:
a) Subtracting the minimum value, so the lowest elevation comes out as a value of zero
b) Running a smoothing algorithm across the DEM to remove noise - Produce a map – either static or web map
March 27, 2025
Test and Code
pytest-html - a plugin that generates HTML reports for test results
pytest-html has got to be one of my all time favorite plugins.
pytest-html is a plugin for pytest that generates a HTML report for test results.
This episode digs into some of the super coolness of pytest-html.
Sponsored by:
- The Complete pytest course is now a bundle, with each part available separately.
- pytest Primary Power teaches the super powers of pytest that you need to learn to use pytest effectively.
- Using pytest with Projects has lots of "when you need it" sections like debugging failed tests, mocking, testing strategy, and CI
- Then pytest Booster Rockets can help with advanced parametrization and building plugins.
- Whether you need to get started with pytest today, or want to power up your pytest skills, PythonTest has a course for you.
Python Anywhere
innit: a new system image, with Python 3.13 and Ubuntu 22.04
If you signed up for an account on PythonAnywhere after 25 March 2025, you’ll have Python versions 3.11, 3.12 and 3.13 available. Additionally, the underlying operating system for your account will be Ubuntu 22.04, rather than the 20.04 used by older accounts.
If you signed up before that date, you’ll be on an older “system image” – essentially the version of the operating system and the set of installed packages that you have access to. You can switch to the new system image from the “Account” page, but you may need to make changes to your code and/or virtualenvs to make everything work – there’s more information on that page.
This post has more details on what’s new in the “innit” system image. There’s a lot!
Real Python
Quiz: Using Python's .__dict__ to Work With Attributes
In this quiz, you’ll test your understanding of Using Python’s .__dict__ to Work With Attributes.
By working through this quiz, you’ll revisit how .__dict__ holds an object’s writable attributes, allowing for dynamic manipulation and introspection. You’ll also review how both vars() and .__dict__ let you inspect an object’s attributes, and the common use cases of .__dict__ in Python applications.
[ Improve Your Python With 🐍 Python Tricks 💌 – Get a short & sweet Python Trick delivered to your inbox every couple of days. >> Click here to learn more and see examples ]
Eli Bendersky
Notes on implementing Attention
Some notes on implementing attention blocks in pure Python + Numpy. The focus here is on the exact implementation in code, explaining all the shapes throughout the process. The motivation for why attention works is not covered here - there are plenty of excellent online resources explaining it.
Several papers are mentioned throughout the code; they are:
- AIAYN - Attention Is All You Need by Vaswani et al.
- GPT-3 - Language Models are Few-Shot Learners by Brown et al.
Basic scaled self-attention
We'll start with the most basic scaled dot product self-attention, working on a single sequence of tokens, without masking.
The input is a 2D array of shape (N, D). N is the length of the sequence (how many tokens it contains) and D is the embedding depth - the length of the embedding vector representing each token [1]. D could be something like 512, or more, depending on the model.
A self-attention module is parameterized with three weight matrices, Wk, Wq and Wv. Some variants also have accompanying bias vectors, but the AIAYN paper doesn't use them, so I'll skip them here. In the general case, the shape of each weight matrix is (D, HS), where HS is some fraction of D. HS stands for "head size" and we'll see what this means soon. This is a diagram of a self-attention module (the diagram assumes N=6, D is some large number and so is HS). In the diagram, @ stands for matrix multiplication (Python/Numpy syntax):
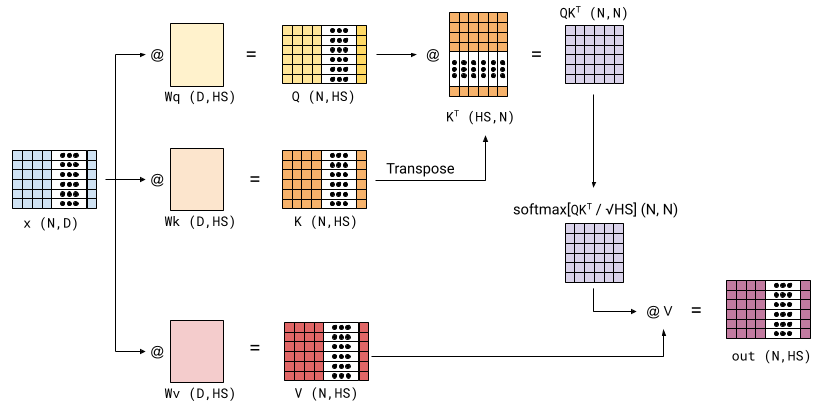
Here's a basic Numpy implementation of this:
# self_attention the way it happens in the Transformer model. No bias.
# D = model dimension/depth (length of embedding)
# N = input sequence length
# HS = head size
#
# x is the input (N, D), each token in a row.
# Each of W* is a weight matrix of shape (D, HS)
# The result is (N, HS)
def self_attention(x, Wk, Wq, Wv):
# Each of these is (N, D) @ (D, HS) = (N, HS)
q = x @ Wq
k = x @ Wk
v = x @ Wv
# kq: (N, N) matrix of dot products between each pair of q and k vectors.
# The division by sqrt(HS) is the scaling.
kq = q @ k.T / np.sqrt(k.shape[1])
# att: (N, N) attention matrix. The rows become the weights that sum
# to 1 for each output vector.
att = softmax_lastdim(kq)
return att @ v # (N, HS)
The "scaled" part is just dividing kq by the square root of HS, which is done to keep the values of the dot products manageable (otherwise they would grow with the size of the contracted dimension).
The only dependency is a function for calculating Softmax across the last dimension of an input array:
def softmax_lastdim(x):
"""Compute softmax across last dimension of x.
x is an arbitrary array with at least two dimensions. The returned array has
the same shape as x, but its elements sum up to 1 across the last dimension.
"""
# Subtract the max for numerical stability
ex = np.exp(x - np.max(x, axis=-1, keepdims=True))
# Divide by sums across last dimension
return ex / np.sum(ex, axis=-1, keepdims=True)
When the input is 2D, the "last dimension" is the columns. Colloquially, this Softmax function acts on each row of x separately; it applies the Softmax formula to the elements (columns) of the row, ending up with a row of numbers in the range [0,1] that all sum up to 1.
Another note on the dimensions: it's possible for the Wv matrix to have a different second dimension from Wq and Wk. If you look at the diagram, you can see this will work out, since the softmax produces (N, N), and whatever the second dimension of V is, will be the second dimension of the output. The AIAYN paper designates these dimensions as d_k and d_v, but in practice d_k=d_v in all the variants it lists. I found that these dimensions are typically the same in other papers as well. Therefore, for simplicity I just made them all equal to D in this post; if desired, a variant with different d_k and d_v is a fairly trivial modification to this code.
Batched self-attention
In the real world, the input array is unlikely to be 2D because models are trained on batches of input sequences. To leverage the parallelism of modern hardware, whole batches are typically processed in the same operation.
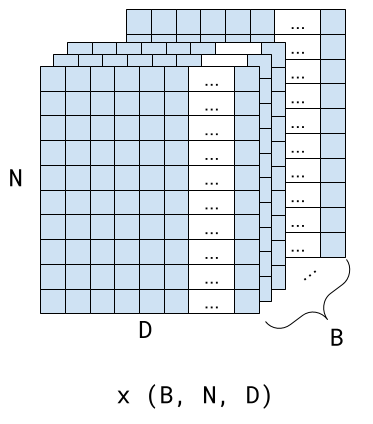
The batched version of scaled self-attention is very similar to the non-batched one, due to the magic of Numpy matrix multiplication and broadcasts. Now the input shape is (B, N, D), where B is the batch dimension. The W* matrices are still (D, HS); multiplying a (B, N, D) array by (D, HS) performs contraction between the last axis of the first array and the first axis of the second array, resulting in (B, N, HS). Here's the code, with the dimensions annotated for each operation:
# self_attention with inputs that have a batch dimension.
# x has shape (B, N, D)
# Each of W* has shape (D, D)
def self_attention_batched(x, Wk, Wq, Wv):
q = x @ Wq # (B, N, HS)
k = x @ Wk # (B, N, HS)
v = x @ Wv # (B, N, HS)
kq = q @ k.swapaxes(-2, -1) / np.sqrt(k.shape[-1]) # (B, N, N)
att = softmax_lastdim(kq) # (B, N, N)
return att @ v # (B, N, HS)
Note that the only difference between this and the non-batched version is the line calculating kq:
- Since k is no longer 2D, the notion of "transpose" is ambiguous so we explicitly ask to swap the last and the penultimate axis, leaving the first axis (B) intact.
- When calculating the scaling factor we use k.shape[-1] to select the last dimension of k, instead of k.shape[1] which only selects the last dimension for 2D arrays.
In fact, this function could also calculate the non-batched version! From now on, we'll assume that all inputs are batched, and all operations are implicitly batched. I'm not going to be using the "batched" prefix or suffix on functions any more.
The basic underlying idea of the attention module is to shift around the multi-dimensional representations of tokens in the sequence towards a better representation of the entire sequence. The tokens attend to each other. Specifically, the matrix produced by the Softmax operation is called the attention matrix. It's (N, N); for each token it specifies how much information from every other token in the sequence should be taken into account. For example, a higher number in cell (R, C) means that there's a stronger relation of token at index R in the sequence to the token at index C.
Here's a nice example from the AIAYN paper, showing a word sequence and the weights produced by two attention heads (purple and brown) for a given position in the input sequence:
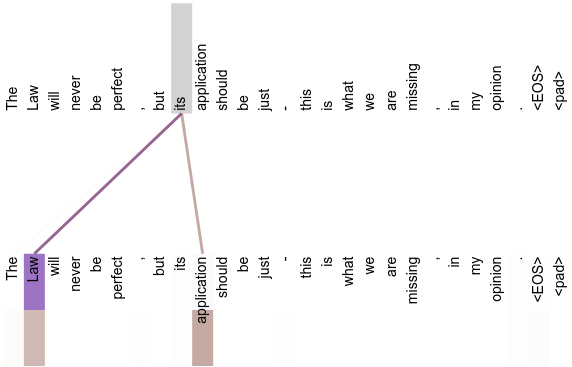
This shows how the model is learning to resolve what the word "its" refers to in the sentence. Let's take just the purple head as an example. The index of token "its" in the sequence is 8, and the index of "Law" is 1. In the attention matrix for this head, the value at index (8, 1) will be very high (close to 1), with other values in the same row much lower.
While this intuitive explanation isn't critical to understand how attention is implemented, it will become more important when we talk about masked self-attention later on.
Multi-head attention
The attention mechanism we've seen so far has a single set of K, Q and V matrices. This is called one "head" of attention. In today's models, there are typically multiple heads. Each head does its attention job separately, and in the end all these results are concatenated and feed through a linear layer.
In what follows, NH is the number of heads and HS is the head size. Typically, NH times HS would be D; for example, the AIAYN paper mentions several configurations for D=512: NH=8 and HS=64, NH=32 and HS=16, and so on [2]. However, the math works out even if this isn't the case, because the final linear ("projection") layer maps the output back to (N, D).
Assuming the previous diagram showing a self-attention module is a single head with input (N, D) and output (N, HS), this is how multiple heads are combined:
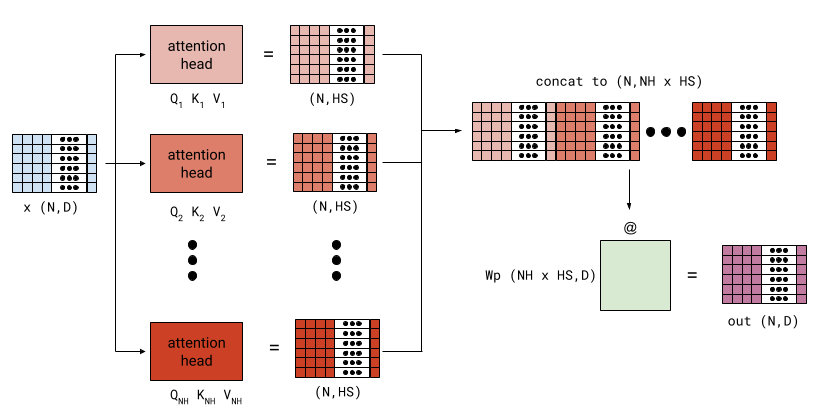
Each of the (NH) heads has its own parameter weights for Q, K and V. Each attention head outputs a (N, HS) matrix; these are concatenated along the last dimension to (N, NH * HS), which is passed through a final linear projection.
Here's a function implementing (batched) multi-head attention; for now, please ignore the code inside do_mask conditions:
# x has shape (B, N, D)
# In what follows:
# NH = number of heads
# HS = head size
# Each W*s is a list of NH weight matrices of shape (D, HS).
# Wp is a weight matrix for the final linear projection, of shape (NH * HS, D)
# The result is (B, N, D)
# If do_mask is True, each attention head is masked from attending to future
# tokens.
def multihead_attention_list(x, Wqs, Wks, Wvs, Wp, do_mask=False):
# Check shapes.
NH = len(Wks)
HS = Wks[0].shape[1]
assert len(Wks) == len(Wqs) == len(Wvs)
for W in Wqs + Wks + Wvs:
assert W.shape[1] == HS
assert Wp.shape[0] == NH * HS
# List of head outputs
head_outs = []
if do_mask:
# mask is a lower-triangular (N, N) matrix, with zeros above
# the diagonal and ones on the diagonal and below.
N = x.shape[1]
mask = np.tril(np.ones((N, N)))
for Wk, Wq, Wv in zip(Wks, Wqs, Wvs):
# Calculate self attention for each head separately
q = x @ Wq # (B, N, HS)
k = x @ Wk # (B, N, HS)
v = x @ Wv # (B, N, HS)
kq = q @ k.swapaxes(-2, -1) / np.sqrt(k.shape[-1]) # (B, N, N)
if do_mask:
# Set the masked positions to -inf, to ensure that a token isn't
# affected by tokens that come after it in the softmax.
kq = np.where(mask == 0, -np.inf, kq)
att = softmax_lastdim(kq) # (B, N, N)
head_outs.append(att @ v) # (B, N, HS)
# Concatenate the head outputs and apply the final linear projection
all_heads = np.concatenate(head_outs, axis=-1) # (B, N, NH * HS)
return all_heads @ Wp # (B, N, D)
It is possible to vectorize this code even further; you'll sometimes see the heads laid out in a separate (4th) dimension instead of being a list. See the Vectorizing across the heads dimension section.
Masked (or Causal) self-attention
Attention modules can be used in both encoder and decoder blocks. Encoder blocks are useful for things like language understanding or translation; for these, it makes sense for each token to attend to all the other tokens in the sequence.
However, for generative models this presents a problem: if during training a word attends to future words, the model will just "cheat" and not really learn how to generate the next word from only past words. This is done in a decoder block, and for this we need to add masking to attention.
Conceptually, masking is very simple. Consider the sentence:
People like watching funny cat videos
When our attention code generates the att matrix, it's a square (N, N) matrix with attention weights from each token to each other token in the sequence:
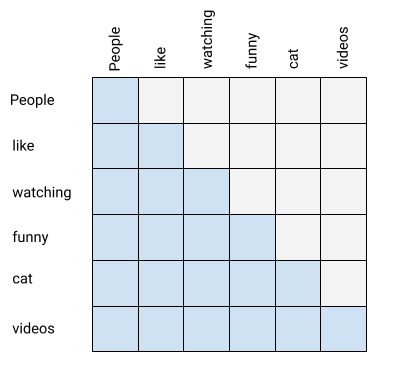
What we want is for all the gray cells in this matrix to be zero, to ensure that a token doesn't attend to future tokens. The blue cells in the matrix add up to 1 in each row, after the softmax operation.
Now take a look at the previous code sample and see what happens when do_mask=True:
- First, a (N, N) lower-triangular array is prepared with zeros above the diagonal and ones on the diagonal and below.
- Then, before we pass the scaled QK^T to softmax, we set its values to -\infty wherever the mask matrix is 0. This ensures that the softmax function will assign zeros to outputs at these indices, while still producing the proper values in the rest of the row.
Another name for masked self-attention is causal self-attention. This is a very good name that comes from causal systems in control theory.
Cross-attention
So far we've been working with self-attention blocks, where the self suggests that elements in the input sequence attend to other elements in the same input sequence.
Another variant of attention is cross-attention, where elements of one sequence attend to elements in another sequence. This variant exists in the decoder block of the AIAYN paper. This is a single head of cross-attention:
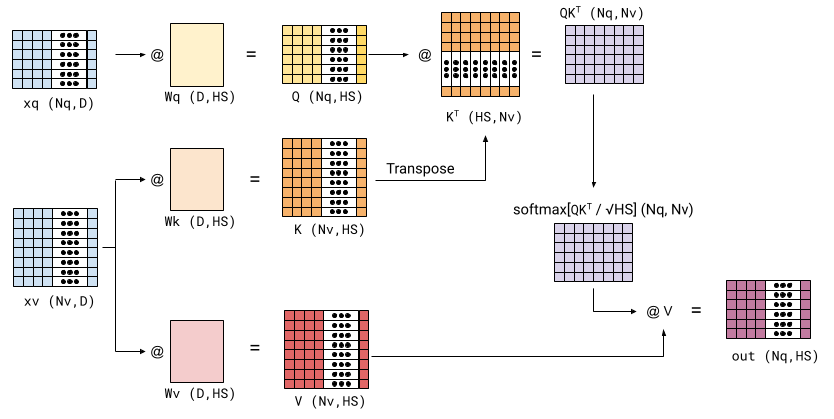
Here we have two sequences with potentially different lengths: xq and xv. xq is used for the query part of attention, while xv is used for the key and value parts. The rest of the dimensions remain as before. The output of such a block is shaped (Nq, HS).
This is an implementation of multi-head cross-attention; it doesn't include masking, since masking is not typically necessary in cross attention - it's OK for elements of xq to attend to all elements of xv [3]:
# Cross attention between two input sequences that can have different lengths.
# xq has shape (B, Nq, D)
# xv has shape (B, Nv, D)
# In what follows:
# NH = number of heads
# HS = head size
# Each W*s is a list of NH weight matrices of shape (D, HS).
# Wp is a weight matrix for the final linear projection, of shape (NH * HS, D)
# The result is (B, Nq, D)
def multihead_cross_attention_list(xq, xv, Wqs, Wks, Wvs, Wp):
# Check shapes.
NH = len(Wks)
HS = Wks[0].shape[1]
assert len(Wks) == len(Wqs) == len(Wvs)
for W in Wqs + Wks + Wvs:
assert W.shape[1] == HS
assert Wp.shape[0] == NH * HS
# List of head outputs
head_outs = []
for Wk, Wq, Wv in zip(Wks, Wqs, Wvs):
q = xq @ Wq # (B, Nq, HS)
k = xv @ Wk # (B, Nv, HS)
v = xv @ Wv # (B, Nv, HS)
kq = q @ k.swapaxes(-2, -1) / np.sqrt(k.shape[-1]) # (B, Nq, Nv)
att = softmax_lastdim(kq) # (B, Nq, Nv)
head_outs.append(att @ v) # (B, Nq, HS)
# Concatenate the head outputs and apply the final linear projection
all_heads = np.concatenate(head_outs, axis=-1) # (B, Nq, NH * HS)
return all_heads @ Wp # (B, Nq, D)
Vectorizing across the heads dimension
The multihead_attention_list implementation shown above uses lists of weight matrices as input. While this makes the code clearer, it's not a particularly friendly format for an optimized implementation - especially on accelerators like GPUs and TPUs. We can vectorize it further by creating a new dimension for attention heads.
To understand the trick being used, consider a basic matmul of (8, 6) by (6, 2):
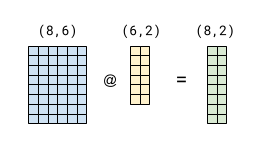
Now suppose we want to multiply our LHS by another (6, 2) matrix. We can do it all in the same operation by concatenating the two RHS matrices along columns:
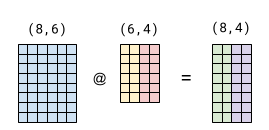
If the yellow RHS block in both diagrams is identical, the green block of the result will be as well. And the violet block is just the matmul of the LHS by the red block of the RHS. This stems from the semantics of matrix multiplication, and is easy to verify on paper.
Now back to our multi-head attention. Note that we multiply the input x by a whole list of weight matrices - in fact, by three lists (one list for Q, one for K, and another for V). We can use the same vectorization technique by concatenating all these weight matrices into a single one. Assuming that NH * HS = D, the shape of the combined matrix is (D, 3 * D). Here's the vectorized implementation:
# x has shape (B, N, D)
# In what follows:
# NH = number of heads
# HS = head size
# NH * HS = D
# W is expected to have shape (D, 3 * D), with all the weight matrices for
# Qs, Ks, and Vs concatenated along the last dimension, in this order.
# Wp is a weight matrix for the final linear projection, of shape (D, D).
# The result is (B, N, D).
# If do_mask is True, each attention head is masked from attending to future
# tokens.
def multihead_attention_vec(x, W, NH, Wp, do_mask=False):
B, N, D = x.shape
assert W.shape == (D, 3 * D)
qkv = x @ W # (B, N, 3 * D)
q, k, v = np.split(qkv, 3, axis=-1) # (B, N, D) each
if do_mask:
# mask is a lower-triangular (N, N) matrix, with zeros above
# the diagonal and ones on the diagonal and below.
mask = np.tril(np.ones((N, N)))
HS = D // NH
q = q.reshape(B, N, NH, HS).transpose(0, 2, 1, 3) # (B, NH, N, HS)
k = k.reshape(B, N, NH, HS).transpose(0, 2, 1, 3) # (B, NH, N, HS)
v = v.reshape(B, N, NH, HS).transpose(0, 2, 1, 3) # (B, NH, N, HS)
kq = q @ k.swapaxes(-1, -2) / np.sqrt(k.shape[-1]) # (B, NH, N, N)
if do_mask:
# Set the masked positions to -inf, to ensure that a token isn't
# affected by tokens that come after it in the softmax.
kq = np.where(mask == 0, -np.inf, kq)
att = softmax_lastdim(kq) # (B, NH, N, N)
out = att @ v # (B, NH, N, HS)
return out.transpose(0, 2, 1, 3).reshape(B, N, D) @ Wp # (B, N, D)
This code computes Q, K and V in a single matmul, and then splits them into separate arrays (note that on accelerators these splits and later transposes may be very cheap or even free as they represent a different access pattern into the same data).
Each of Q, K and V is initially (B, N, D), so they are reshaped into a more convenient shape by first splitting the D into (NH, HS), and finally changing the order of dimensions to get (B, NH, N, HS). In this format, both B and NH are considered batch dimensions that are fully parallelizable. The QK^T computation can then proceed as before, and Numpy will automatically perform the matmul over all the batch dimensions.
Sometimes you'll see an alternative notation used in papers for these matrix multiplications: numpy.einsum. For example, in our last code sample the computation of kq could also be written as:
kq = np.einsum("bhqd,bhkd->bhqk", q, k) / np.sqrt(k.shape[-1])
Code
The full code for these samples, with tests, is available in this repository.
| [1] | In LLM papers, D is often called d_{model}. |
| [2] | In the GPT-3 paper, this is also true for all model variants. For example, the largest 175B model has NH=96, HS=128 and D=12288. |
| [3] | It's also not as easy to define mathematically: how do we make a non-square matrix triangular? And what does it mean when the lengths of the two inputs are different? |
Armin Ronacher
Rust Any Part 3: Finally we have Upcasts
Three years ago I shared the As-Any Hack on this blog. That hack is a way to get upcasting to supertraits working on stable Rust. To refresh your memory, the goal was to make something like this work:
#[derive(Debug)]
struct AnyBox(Box<dyn DebugAny>);
trait DebugAny: Any + Debug {}
impl<T: Any + Debug + 'static> DebugAny for T {}
The problem? Even though DebugAny inherits from Any, Rust wouldn't let you use methods from Any on a dyn DebugAny. So while you could call DebugAny methods just fine, trying to use downcast_ref from Any (the reason to use Any in the first place) would fail:
fn main() {
let any_box = AnyBox(Box::new(42i32));
dbg!(any_box.0.downcast_ref::<i32>()); // Compile error
}
The same would happen if we tried to cast it into an &dyn Any? A compile error again:
fn main() {
let any_box = AnyBox(Box::new(42i32));
let any = &*any_box.0 as &dyn Any;
dbg!(any.downcast_ref::<i32>());
}
But there is good news! As of Rust 1.86, this is finally fixed. The cast now works:
[src/main.rs:14:5] any.downcast_ref::<i32>() = Some(
42,
)
At the time of writing, this fix is in the beta channel, but stable release is just around the corner. That means a lot of old hacks can finally be retired. At least once your MSRV moves up.
Thank you so much to everyone who worked on this to make it work!
For completeness' sake here is the extension map from the original block post cleaned up so that it does not need the as-any hack:
use std::any::{Any, TypeId};
use std::cell::{Ref, RefCell, RefMut};
use std::collections::HashMap;
use std::fmt::Debug;
trait DebugAny: Any + Debug {}
impl<T: Any + Debug + 'static> DebugAny for T {}
#[derive(Default, Debug)]
pub struct Extensions {
map: RefCell<HashMap<TypeId, Box<dyn DebugAny>>>,
}
impl Extensions {
pub fn insert<T: Debug + 'static>(&self, value: T) {
self.map
.borrow_mut()
.insert(TypeId::of::<T>(), Box::new(value));
}
pub fn get<T: Default + Debug + 'static>(&self) -> Ref<'_, T> {
self.ensure::<T>();
Ref::map(self.map.borrow(), |m| {
m.get(&TypeId::of::<T>())
.and_then(|b| (&**b as &dyn Any).downcast_ref())
.unwrap()
})
}
pub fn get_mut<T: Default + Debug + 'static>(&self) -> RefMut<'_, T> {
self.ensure::<T>();
RefMut::map(self.map.borrow_mut(), |m| {
m.get_mut(&TypeId::of::<T>())
.and_then(|b| ((&mut **b) as &mut dyn Any).downcast_mut())
.unwrap()
})
}
fn ensure<T: Default + Debug + 'static>(&self) {
if self.map.borrow().get(&TypeId::of::<T>()).is_none() {
self.insert(T::default());
}
}
}
meejah.ca
Magic Wormhole is What?
Various levels of details regarding a secure peer connection technology
March 26, 2025
Python Morsels
Checking whether iterables are equal in Python
You can check whether iterables contain the same elements in Python with equality checks, type conversions, sets, Counter, or looping helpers.

Table of contents
Simple equality checks
If we have two lists and we wanted to know whether the items in these two lists are the same, we could use the equality operator (==):
>>> lines1 = ["Grains", "Kindred", "Zia"]
>>> lines2 = ["Grains", "Kindred", "Zia"]
>>> lines1 == lines2
True
The same thing works for comparing tuples:
>>> p = (3, 4, 8)
>>> q = (3, 5, 7)
>>> p == q
False
But what if we wanted to compare a list and a tuple?
We can't use a simple equality check for that:
>>> lines1 = ["Grains", "Kindred", "Zia"]
>>> lines2 = ("Grains", "Kindred", "Zia")
>>> lines1 == lines2
False
Comparing different types of iterables
To compare the items in …
Read the full article: https://www.pythonmorsels.com/iterable-equality/
Mirek Długosz
Interesting bugs: peculiar intermittent failure in testing pipeline
Over the years I have encountered my share of memorable problems. They were remarkably complex, hard to debug, completely obvious in retrospect, or plain funny. This is the story of one of them.
At the beginning, there was a suite of automated tests that I was maintaining. One day one of them failed. Not a big deal, unfortunate reality is that some of them fail sometimes for various reasons. Usually they pass when run again and we can blame unreliable infrastructure, transient networking issue or misalignment of the stars. But few days later the same test failed again. And then again. It was clear that there’s something going on and this particular test is intermittently failing. I had to figure out what is happening and how can I make the test provide the same result reliably.
(Note the choice of words here. My goal was not to make the test passing, or “green”. There might as well have been a bug in the test itself, or in the product. At this point nobody knew. The main goal was understanding the issue and making sure test is reliably providing the same result - whether it is pass or fail.)
Before we move on, there’s some relevant context that I need to share. That suite contained only UI tests. Running them all took about an hour. They were running against staging environment few times a day. The test that was failing was responsible for checking a chart which plots the data from last 30 days. There were other tests verifying other charts, sometimes using different time spans. The website used the same generic chart component in all cases. These other tests never failed.
On a high level, the failing test consisted of three main steps: request the data from last 30 days using the API, read the data from the graph on the website, and compare both. Test was considered failed if there was any difference between the data from these two sources. Python deepdiff package was used for comparison. To make it possible, data from API was locally transformed to mimic the structure returned by function responsible for reading the data from UI.
Testing infrastructure had few distinct pieces. There was a Jenkins server that triggered a test suite run at certain times of the day. Job executors were containers in a Kubernetes cluster. To facilitate UI testing, there was a Selenium Grid server with few workers hosted as virtual machines on OpenStack. Tests were running against staging environment of the product, which was also hosted on a Kubernetes cluster, but different than the one where job executors were. I believe all that was scattered across two data centers, with most of testing infrastructure being co-located, and product under test being elsewhere.
 Not necessarily accurate illustration of infrastructure.
Not necessarily accurate illustration of infrastructure.
Now, let’s get back to the story.
The very first thing I did was looking into test logs. Unfortunately, differences between objects as reported by deepdiff in this particular case are not easy to read (see below). The amount of data is overwhelming, and displaying everything in single line contributes to the challenge. The log made it clear that lists returned by API and read from UI are different, but it was not immediately obvious where exactly these differences are.
> assert not deepdiff.DeepDiff(expected_graph_data, actual_graph_data)
E assert not {'values_changed': {"root[0]['Date']": {'new_value': '1970-01-01', 'old_value': '1970-01-02'}, "root[0]['Foo']": {'new_value': 46, 'old_value': 23}, "root[0]['Bar']": {'new_value': 60, 'old_value': 99}, "root[0]['Total']": {'new_value': 106, 'old_value': 122}, "root[1]['Date']": {'new_value': '1970-01-02', 'old_value': '1970-01-03'}, "root[1]['Foo']": {'new_value': 23, 'old_value': 26}, "root[1]['Bar']": {'new_value': 99, 'old_value': 92}, "root[1]['Total']": {'new_value': 122, 'old_value': 118}, "root[2]['Date']": {'new_value': '1970-01-03', 'old_value': '1970-01-04'}, "root[2]['Foo']": {'new_value': 26, 'old_value': 49}, "root[2]['Bar']": {'new_value': 92, 'old_value': 86}, "root[2]['Total']": {'new_value': 118, 'old_value': 135}, "root[3]['Date']": {'new_value': '1970-01-04', 'old_value': '1970-01-05'}, "root[3]['Foo']": {'new_value': 49, 'old_value': 68}, "root[3]['Bar']": {'new_value': 86, 'old_value': 60}, "root[3]['Total']": {'new_value': 135, 'old_value': 128}, "root[4]['Date']": {'new_value': '1970-01-05', 'old_value': '1970-01-06'}, "root[4]['Foo']": {'new_value': 68, 'old_value': 33}, "root[4]['Bar']": {'new_value': 60, 'old_value': 14}, "root[4]['Total']": {'new_value...ue': 25}, "root[24]['Bar']": {'new_value': 29, 'old_value': 78}, "root[24]['Total']": {'new_value': 106, 'old_value': 103}, "root[25]['Date']": {'new_value': '1970-01-26', 'old_value': '1970-01-27'}, "root[25]['Foo']": {'new_value': 25, 'old_value': 57}, "root[25]['Bar']": {'new_value': 78, 'old_value': 84}, "root[25]['Total']": {'new_value': 103, 'old_value': 141}, "root[26]['Date']": {'new_value': '1970-01-27', 'old_value': '1970-01-28'}, "root[26]['Foo']": {'new_value': 57, 'old_value': 48}, "root[26]['Bar']": {'new_value': 84, 'old_value': 18}, "root[26]['Total']": {'new_value': 141, 'old_value': 66}, "root[27]['Date']": {'new_value': '1970-01-28', 'old_value': '1970-01-29'}, "root[27]['Foo']": {'new_value': 48, 'old_value': 89}, "root[27]['Bar']": {'new_value': 18, 'old_value': 14}, "root[27]['Total']": {'new_value': 66, 'old_value': 103}, "root[28]['Date']": {'new_value': '1970-01-29', 'old_value': '1970-01-30'}, "root[28]['Foo']": {'new_value': 89, 'old_value': 61}, "root[28]['Bar']": {'new_value': 14, 'old_value': 66}, "root[28]['Total']": {'new_value': 103, 'old_value': 127}}, 'iterable_item_added': {'root[29]': {'Date': '1970-01-30', 'Foo': 61, 'Bar': 66, 'Total': 127}}}
Trying to understand this log felt daunting, so my next step was running the failing test locally, in isolation. Predictably, it passed. I didn’t have the high hopes that I will be able to reproduce the problem right away, but that was a cheap thing to try, so I think it was worth giving a shot.
At this point I decided there is no way around it and I have to better understand how API and UI responses are different. I copied the log line into editor and inserted a new line character after each },. Few more changes later I had a form that was a little easier to decipher.
Deepdiff shows the differences between elements under the same index in lists. But focusing on elements with the same date value revealed that they are fundamentally the same. Values appearing under “old_value” in one list appears as “new_value” in the other list, just under different index. I have put colored overlay on the screenshot below to make it easier to see. You can think of these lists as mostly the same, but one is shifted when compared to other; or you can say that one list has extra element added at the end, while the other has extra element added at the very beginning. Specifically, API read data from January 2nd to February 1st, but UI displayed data from January 1st to January 31st. There’s a large overlap, but deepdiff output obscured this key insight.
 Deepdiff output after editing. Color overlays shows that both lists have the same data, but in different places.
Deepdiff output after editing. Color overlays shows that both lists have the same data, but in different places.
At this point I had an idea what is wrong, but I had no clue why, and why it would affect only this one single test. So in the next step I wanted to see if there are any patterns to the failure. I grabbed test results from last few weeks and put them in the spreadsheet. I added columns for basic things, like the result itself, how long did it take for test to finish, date and time when test was run. To make failing tests visually distinct, I added background color to highlight them. In separate column I tagged all rows where test was running for a first time in a given day. Then I added columns representing known issues that we encountered in previous few weeks, to see if all failures fall into one of them.
While there wasn’t a clear and predictable pattern, I did notice a curious thing - if the test failed, it would fail in the first run of a given day. Subsequent runs of any day never failed. And the first run in a day always started shortly after midnight UTC.

That allowed me to construct a working hypothesis: the issue is somehow related to time and there’s only a short window when it may occur, maybe up to few hours. That window is located around midnight UTC. Such hypothesis explains why subsequent pipeline runs never failed, and why I was never successful at reproducing the issue locally - I am located east of UTC line and I would have to try running the test way outside of working hours. Of course I didn’t know if I was up to something or I was just creating complex ad hoc hypothesis that fits the data. But it directed my next step.
To corroborate the hypothesis I needed some new information, things I didn’t have before. To gather it, I have added further logging in the test suite. First, I have used Selenium JavaScript execution capability to obtain the date and time as the browser “sees” it. Then I have done the same from Python, which both drives Selenium and requests data from API. The important part is that Python code is executed directly on test runner (container in Kubernetes) and JavaScript code is executed in the browser (Selenium Grid VM on OpenStack).
diff --git package/tests/ui/test_failing.py package/tests/ui/test_failing.py
index 1234567..abcdef0 100644
--- package/tests/ui/test_failing.py
+++ package/tests/ui/test_failing.py
@@ -10,6 +10,13 @@ def test_failing_test(user_app, some_fixture):
"""
view = navigate_to(user_app.some_app, "SomeViewName")
+ browser_time_string = view.browser.execute_script("return new Date().toTimeString()")
+ browser_utc_string = view.browser.execute_script("return new Date().toUTCString()")
+ view.logger.info(
+ "[JavaScript] Time right now: %s ; UTC time: %s",
+ browser_time_string,
+ browser_utc_string,
+ )
expected_x_axis = get_xaxis_values()
view.items.item_select(some_value)
view.graph.wait_displayed()
diff --git package/utils/utils.py package/utils/utils.py
index 1234567..abcdef0 100644
--- package/utils/utils.py
+++ package/utils/utils.py
@@ -10,6 +10,14 @@ METRIC_MAP = {
def _get_dates_range(some_param="Daily", date=None):
+ current_time = arrow.now()
+ log.info(
+ "[Python] Time right now: %s ; TZ name: %s ; TZ offset: %s ; UTC time: %s",
+ current_time,
+ current_time.strftime("%Z"),
+ current_time.strftime("%z"),
+ arrow.utcnow(),
+ )
try:
date = arrow.get(date)
except TypeError:
With the above patch applied and deployed, all I needed to do was waiting for the next failure. I hoped that new logs would reveal some more information once it fails again.
That turned out to be true. JavaScript showed a date one day earlier than Python. In fact, the time in JavaScript was about 15 minutes earlier than in Python. So if test suite ran around midnight, and we got to offending test within 15 minutes of suite start, then Python would request data through API for some dates, but website in browser would think it is still the previous day, and request different set of dates. It means that the window where issue occurs is extremely small - just around 15 minutes each day.
[JavaScript] Time right now: Thu Jan 01 1970 23:58:17 GMT+0000 (Coordinated Universal Time) ; UTC time: Thu, 01 Jan 1970 23:58:17GMT
[Python] Time right now: 1970-01-02T00:14:36.042473+00:00 ; TZ name: UTC ; TZ offset: +0000 ; UTC time: 1970-01-02T00:14:36.042473+00:00
This concludes the main part of the debugging story - at this point we knew what is wrong, we knew that failure is not caused by a bug in a test or a product, and it was clear that the solution is for all machines involved in testing to reconcile date and time. It also seemed like the JavaScript shows wrong date, which might mean that the issue is with Selenium Grid machines or OpenStack instance.
I connected to all Selenium Grid machines using SSH and checked their local time using date command. They were about 15 minutes behind their wall-clock time. I assumed the difference is caused by various OpenStack and underlying infrastructure maintenance work, so I just used hwclock to force OS clock to synchronize with hardware clock and moved on with my day.
Couple of days later I connected to these machines again and noticed that the local time is behind again, but only by about 15 seconds. It looked like the local clock is drifting by about 5 seconds a day. It might not sound like much, but it also meant that it’s only a matter of time before original issue happens again. Clearly someone logging in to these machines every once in a while and resetting clock would not be a good long term solution - we needed something that can automatically keep time synchronized.
That something is called NTP and all the machines already had chrony installed. However, it didn’t seem to work correctly. While the commands succeeded and logs did not show any problems, the clock would just not change. After few frustrating hours I think I ruled out all possible causes at the operating system level and came to the conclusion that perhaps the NTP traffic to public servers is blocked by data center firewall. I reached out to OpenStack administrators for help and they told me that there is a blessed NTP server instance inside the data center that I should use. Once I configured chrony to use it as a source, everything finally worked.
This way browsers started to consistently report the same time as Python executors. That fixed the original issue and we did not observe any test failures caused by it again.
Real Python
Introducing DuckDB
The DuckDB database provides a seamless way to handle large datasets in Python with Online Analytical Processing (OLAP) optimization. You can create databases, verify data imports, and perform efficient data queries using both SQL and DuckDB’s Python API.
By the end of this tutorial, you’ll understand that:
- You can create a DuckDB database by reading data from files like Parquet, CSV, or JSON and saving it to a table.
- You query a DuckDB database using standard SQL syntax within Python by executing queries through a DuckDB connection object.
- You can also use DuckDB’s Python API, which uses method chaining for an object-oriented approach to database queries.
- Concurrent access in DuckDB allows multiple reads but restricts concurrent writes to ensure data integrity.
- DuckDB integrates with pandas and Polars by converting query results into DataFrames using the
.df()or.pl()methods.
The tutorial will equip you with the practical knowledge necessary to get started with DuckDB, including its Online Analytical Processing (OLAP) features, which enable fast access to data through query optimization and buffering.
Ideally, you should already have a basic understanding of SQL, particularly how its SELECT keyword can be used to read data from a relational database. However, the SQL language is very user-friendly, and the examples used here are self-explanatory.
Now, it’s time for you to start learning why there’s a growing buzz surrounding DuckDB.
Get Your Code: Click here to download the free sample code that shows you how to use DuckDB in Python.
Take the Quiz: Test your knowledge with our interactive “Introducing DuckDB” quiz. You’ll receive a score upon completion to help you track your learning progress:
Interactive Quiz
Introducing DuckDBThis quiz will challenge your knowledge of working with DuckDB. You won't find all the answers in the tutorial, so you'll need to do some extra investigation. By finding all the answers, you're sure to learn some interesting things along the way.
Getting Started With DuckDB
To use DuckDB, you first need to install it. Fortunately, DuckDB is self-contained, meaning it won’t interfere with your existing Python environment.
You use python -m pip install duckdb to install it from the command prompt. If you’re working in a Jupyter Notebook, the command becomes !python -m pip install duckdb. The supporting downloadable code for this tutorial is also presented in a Jupyter Notebook.
Once the installation is complete, you can quickly test your installation with a query:
>>> import duckdb
>>> duckdb.sql("SELECT 'whistling_duck' AS waterfowl, 'whistle' AS call")
┌────────────────┬─────────┐
│ waterfowl │ call │
│ varchar │ varchar │
├────────────────┼─────────┤
│ whistling_duck │ whistle │
└────────────────┴─────────┘
To test that everything works, you first import the duckdb library before running a test SQL query. In SQL, a query is a command you use to interact with the data in your database. You commonly use queries to view, add, update, and delete your data.
In this example, you write a SQL SELECT statement to view some data defined by the query. By passing it to the sql() function, you run the query and produce the result shown.
Your query creates a table with two columns named waterfowl and call. These contain the data "whistling_duck" and "whistle", respectively. The data types of both columns are varchar, which is the data type DuckDB uses to store variable-length character strings. Running your query using duckdb.sql() uses the default in-memory database. This means that the data are temporary and will disappear when you end your Python session.
If you see the output shown above, your installation is working perfectly.
Note: DuckDB queries are not case-sensitive. However, writing reserved SQL keywords in uppercase is standard practice. Also, a terminating semicolon (;) is optional in SQL and isn’t used in this tutorial, though you may encounter it elsewhere.
Now that you know how to set things up, it’s time to dive into some of the features that make DuckDB easy to use. In the next section, you’ll create a database table using data imported from an existing file. You’ll also learn how to check that the data has been imported correctly.
Creating a Database From a Data Source
While it’s possible to create database tables using SQL, it’s more common to read data from an external file, perhaps one containing data you’ve extracted from another system, and allow DuckDB to create and populate the table.
DuckDB supports reading from and writing to a range of common file types such as Parquet, CSV, and JSON. In this example, you’ll use data stored in the presidents.parquet Parquet file included in your downloadable materials to create a table.
The presidents.parquet file contains the following six fields:
| Heading | Meaning | Data Type |
|---|---|---|
sequence |
Order of presidency | int64 |
last_name |
President’s last name | varchar |
first_name |
President’s first name | varchar |
term_start |
Start of presidency term | date |
term_end |
End of presidency term | date |
party_id |
Number representing political party | int64 |
When you import data, it gets placed into a DuckDBPyRelation object. In DuckDB, a relation stores a query definition but not its data. To see the data your relation represents, you must do so interactively by viewing it or running an SQL query against it to see specific data.
Read the full article at https://realpython.com/python-duckdb/ »
[ Improve Your Python With 🐍 Python Tricks 💌 – Get a short & sweet Python Trick delivered to your inbox every couple of days. >> Click here to learn more and see examples ]
Python GUIs
Multithreading PySide6 applications with QThreadPool — Run background tasks concurrently without impacting your UI
A common problem when building Python GUI applications is the interface "locking up" when attempting to perform long-running background tasks. In this tutorial, we'll cover quick ways to achieve concurrent execution in PySide6.
If you'd like to run external programs (such as command-line utilities) from your applications, check out the Using QProcess to run external programs tutorial.
Background: The frozen GUI issue
Applications based on Qt (like most GUI applications) are based on events. This means that execution is driven in response to user interaction, signals, and timers. In an event-driven application, clicking a button creates an event that your application subsequently handles to produce some expected output. Events are pushed onto and taken off an event queue and processed sequentially.
In PySide6, we create an app with the following code:
app = QApplication([])
window = MainWindow()
app.exec()
The event loop starts when you call .exec() on the QApplication object and runs within the same thread as your Python code. The thread that runs this event loop — commonly referred to as the GUI thread — also handles all window communication with the host operating system.
By default, any execution triggered by the event loop will also run synchronously within this thread. In practice, this means that the time your PySide6 application spends doing something, the communication with the window and the interaction with the GUI are frozen.
If what you're doing is simple, and it returns control to the GUI loop quickly, the GUI freeze will be imperceptible to the user. However, if you need to perform longer-running tasks, for example, opening and writing a large file, downloading some data, or rendering a high-resolution image, there are going to be problems.
To your user, the application will appear to be unresponsive (because it is). Because your app is no longer communicating with the OS, on macOS, if you click on your app, you will see the spinning wheel of death. And, nobody wants that.
The solution is to move your long-running tasks out of the GUI thread into another thread. PySide6 provides a straightforward interface for this.
Preparation: A minimal stub app
To demonstrate multi-threaded execution, we need an application to work with. Below is a minimal stub application for PySide6 that will allow us to demonstrate multithreading and see the outcome in action. Simply copy and paste this into a new file and save it with an appropriate filename, like multithread.py. The remainder of the code will be added to this file. There is also a complete working example at the bottom if you're impatient:
import time
from PySide6.QtCore import (
QTimer,
)
from PySide6.QtWidgets import (
QApplication,
QLabel,
QMainWindow,
QPushButton,
QVBoxLayout,
QWidget,
)
class MainWindow(QMainWindow):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
self.counter = 0
layout = QVBoxLayout()
self.label = QLabel("Start")
button = QPushButton("DANGER!")
button.pressed.connect(self.oh_no)
layout.addWidget(self.label)
layout.addWidget(button)
w = QWidget()
w.setLayout(layout)
self.setCentralWidget(w)
self.show()
self.timer = QTimer()
self.timer.setInterval(1000)
self.timer.timeout.connect(self.recurring_timer)
self.timer.start()
def oh_no(self):
time.sleep(5)
def recurring_timer(self):
self.counter += 1
self.label.setText(f"Counter: {self.counter}")
app = QApplication([])
window = MainWindow()
app.exec()
Run the app as for any other Python application:
$ python multithread.py
You will see a demonstration window with a number counting upwards. This count is generated by a simple recurring timer, firing once per second. Think of this as our event loop indicator (or GUI thread indicator), a simple way to let us know that our application is ticking over normally. There is also a button with the word "DANGER!. Push it.
You'll notice that each time you push the button, the counter stops ticking, and your application freezes entirely. On Windows, you may see the window turn pale, indicating it is not responding, while on macOS, you'll get the spinning wheel of death.
The wrong approach
Avoid doing this in your code.
What appears as a frozen interface is the main Qt event loop being blocked from processing (and responding to) window events. Your clicks on the window are still registered by the host OS and sent to your application, but because it's sat in your big ol' lump of code (calling time.sleep()), it can't accept or react to them. They have to wait until your code passes control back to Qt.
The quickest and perhaps most logical way to get around this issue is to accept events from within your code. This allows Qt to continue to respond to the host OS and your application will stay responsive. You can do this easily by using the static processEvents() method on the QApplication class.
For example, our long-running code time.sleep() could be broken down into five 1-second sleeps and
insert the processEvents() in between. The code for this would be:
def oh_no(self):
for n in range(5):
QApplication.processEvents()
time.sleep(1)
Now, when you push the DANGER! button, your app runs as before. However, now QApplication.processEvents() intermittently passes control back to Qt, and allows it to respond to events as normal. Qt will then accept events and handle them before returning to run the remainder of your code.
This approach works, but it's horrible for a few reasons, including the following:
-
When you pass control back to Qt, your code is no longer running. This means that whatever long-running task you're trying to do will take longer. That is definitely not what you want.
-
When you have multiple long-running tasks within your application, with each calling
QApplication.processEvents()to keep things ticking, your application's behavior can be unpredictable. -
Processing events outside the main event loop (
app.exec()) causes your application to branch off into handling code (e.g. for triggered slots or events) while within your loop. If your code depends on or responds to an external state, then this can cause undefined behavior.
The code below demonstrates the last point in action:
import time
from PySide6.QtCore import (
QTimer,
)
from PySide6.QtWidgets import (
QApplication,
QLabel,
QMainWindow,
QPushButton,
QVBoxLayout,
QWidget,
)
class MainWindow(QMainWindow):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
self.counter = 0
layout = QVBoxLayout()
self.label = QLabel("Start")
button = QPushButton("DANGER!")
button.pressed.connect(self.oh_no)
c = QPushButton("?")
c.pressed.connect(self.change_message)
layout.addWidget(self.label)
layout.addWidget(button)
layout.addWidget(c)
w = QWidget()
w.setLayout(layout)
self.setCentralWidget(w)
self.show()
self.timer = QTimer()
self.timer.setInterval(1000)
self.timer.timeout.connect(self.recurring_timer)
self.timer.start()
def change_message(self):
self.message = "OH NO"
def oh_no(self):
self.message = "Pressed"
for n in range(100):
time.sleep(0.1)
self.label.setText(self.message)
QApplication.processEvents()
def recurring_timer(self):
self.counter += 1
self.label.setText(f"Counter: {self.counter}")
app = QApplication([])
window = MainWindow()
app.exec()
If you run this code you'll see the counter as before. Pressing DANGER! will change the displayed text to "Pressed", as defined at the entry point to the oh_no() method. However, if you press the "?" button while oh_no() is still running, you'll see that the message changes. The state is being changed from outside your event loop.
Use threads and processes
If you take a step back and think about what you want to happen in your application, then you can probably sum it up with "stuff to happen at the same time as other stuff happens".
There are two main approaches to running independent tasks within a PySide6 application:
- Threads
- Processes
Threads share the same memory space, so they are quick to start up and consume minimal resources. The shared memory makes it trivial to pass data between threads. However, reading or writing memory from different threads can lead to race conditions or segfaults.
In Python, there is the added issue that multiple threads are bound by the Global Interpreter Lock (GIL) — meaning non-GIL-releasing Python code can only execute in one thread at a time. However, this is not a major issue with PySide6, where most of the time is spent outside of Python.
Processes use separate memory space and an entirely separate Python interpreter. They sidestep any potential problems with Python's GIL but at the cost of slower start-up times, larger memory overhead, and complexity in sending and receiving data.
Processes in Qt are well suited to running and communicating with external programs. However, for simplicity's sake, threads are usually the best choice unless you have a good reason to use processes (see caveats later).
There is nothing stopping you from using pure Python threading or process-based approaches within your PySide6 application. In the following sections, though, you'll rely on Qt's threading classes.
QRunnable and the QThreadPool
Favor this approach in your code.
Qt provides a straightforward interface for running jobs or tasks in other threads, which is nicely supported in PySide6. This interface is built around two classes:
QRunnable: The container for the work you want to perform.QThreadPool: The method by which you pass that work to alternate threads.
The neat thing about using QThreadPool is that it handles queuing and executing workers for you. Other than queuing up jobs and retrieving the results, there is not much to do.
To define a custom QRunnable, you can subclass the base QRunnable class. Then, place the code you wish you execute within the run() method. The following is an implementation of our long-running time.sleep() job as a QRunnable.
Go ahead and add the following code to multithread.py, above the MainWindow class definition, and don't forget to import QRunnable and Slot from PySide6.QtCore:
class Worker(QRunnable):
"""Worker thread."""
@Slot()
def run(self):
"""Your long-running job goes in this method."""
print("Thread start")
time.sleep(5)
print("Thread complete")
Executing our long-running job in another thread is simply a matter of creating an instance of the Worker and passing it to our QThreadPool instance. It will be executed automatically.
Next, import QThreadPool from PySide6.QtCore and add the following code to the __init__() method to set up our thread pool:
self.threadpool = QThreadPool()
thread_count = self.threadpool.maxThreadCount()
print(f"Multithreading with maximum {thread_count} threads")
Finally, update the oh_no() method as follows:
def oh_no(self):
worker = Worker()
self.threadpool.start(worker)
Now, clicking the DANGER! button will create a worker to handle the (long-running) job and spin that off into another thread via thread pool. If there are not enough threads available to process incoming workers, they'll be queued and executed in order at a later time.
Try it out, and you'll see that your application now handles you bashing the button with no problems.
Check what happens if you hit the button multiple times. You should see your threads executed immediately up to the number reported by maxThreadCount(). If you press the button again after there are already this number of active workers, then the subsequent workers will be queued until a thread becomes available.
Improved QRunnable
If you want to pass custom data into the runner function, you can do so via __init__(), and then have access to the data via self from within the run() slot:
class Worker(QRunnable):
"""Worker thread.
:param args: Arguments to make available to the run code
:param kwargs: Keywords arguments to make available to the run code
"""
def __init__(self, *args, **kwargs):
super().__init__()
self.args = args
self.kwargs = kwargs
@Slot()
def run(self):
"""Initialise the runner function with passed self.args, self.kwargs."""
print(self.args, self.kwargs)
We can take advantage of the fact that Python functions are objects and pass in the function to execute rather than subclassing QRunnable for each runner function. In the following construction, we only require a single Worker class to handle all of our jobs:
class Worker(QRunnable):
"""Worker thread.
Inherits from QRunnable to handler worker thread setup, signals and wrap-up.
:param callback: The function callback to run on this worker thread.
Supplied args and kwargs will be passed through to the runner.
:type callback: function
:param args: Arguments to pass to the callback function
:param kwargs: Keywords to pass to the callback function
"""
def __init__(self, fn, *args, **kwargs):
super().__init__()
self.fn = fn
self.args = args
self.kwargs = kwargs
@Slot()
def run(self):
"""Initialise the runner function with passed args, kwargs."""
self.fn(*self.args, **self.kwargs)
You can now pass in any Python function and have it executed in a separate thread. Go ahead and update MainWindow with the following code:
def execute_this_fn(self):
print("Hello!")
def oh_no(self):
# Pass the function to execute
worker = Worker(
self.execute_this_fn
) # Any other args, kwargs are passed to the run function
# Execute
self.threadpool.start(worker)
Now, when you click DANGER!, the app will print Hello! to your terminal without affecting the counter.
Thread Input/Output
Sometimes, it's helpful to be able to pass back state and data from running workers. This could include the outcome of calculations, raised exceptions, or ongoing progress (maybe for progress bars). Qt provides the signals and slots framework to allow you to do just that. Qt's signals and slots are thread-safe, allowing safe communication directly from running threads to your GUI thread.
Signals allow you to emit values, which are then picked up elsewhere in your code by slot functions that have been linked with the connect() method.
Below is a custom WorkerSignals class defined to contain a number of example signals. Note that custom signals can only be defined on objects derived from QObject. Since QRunnable is not derived from QObject we can't define the signals there directly. A custom QObject to hold the signals is a quick solution:
class WorkerSignals(QObject):
"""Signals from a running worker thread.
finished
No data
error
tuple (exctype, value, traceback.format_exc())
result
object data returned from processing, anything
"""
finished = Signal()
error = Signal(tuple)
result = Signal(object)
In this code, we've defined three custom signals:
finished, which receives no data and is aimed to indicate when the task is complete.error, which receives atupleofExceptiontype,Exceptionvalue, and formatted traceback.result, which receives anyobjecttype from the executed function.
You may not find a need for all of these signals, but they are included to give an indication of what is possible. In the following code, we're going to implement a long-running task that makes use of these signals to provide useful information to the user:
class Worker(QRunnable):
"""Worker thread.
Inherits from QRunnable to handler worker thread setup, signals and wrap-up.
:param callback: The function callback to run on this worker thread.
Supplied args and
kwargs will be passed through to the runner.
:type callback: function
:param args: Arguments to pass to the callback function
:param kwargs: Keywords to pass to the callback function
"""
def __init__(self, fn, *args, **kwargs):
super().__init__()
self.fn = fn
self.args = args
self.kwargs = kwargs
self.signals = WorkerSignals()
@Slot()
def run(self):
"""Initialise the runner function with passed args, kwargs."""
# Retrieve args/kwargs here; and fire processing using them
try:
result = self.fn(*self.args, **self.kwargs)
except Exception:
traceback.print_exc()
exctype, value = sys.exc_info()[:2]
self.signals.error.emit((exctype, value, traceback.format_exc()))
else:
self.signals.result.emit(result) # Return the result of the processing
finally:
self.signals.finished.emit() # Done
You can connect your own handler functions to the signals to receive notification of completion (or the result) of threads:
def execute_this_fn(self):
for n in range(0, 5):
time.sleep(1)
return "Done."
def print_output(self, s):
print(s)
def thread_complete(self):
print("THREAD COMPLETE!")
def oh_no(self):
# Pass the function to execute
worker = Worker(
self.execute_this_fn
) # Any other args, kwargs are passed to the run function
worker.signals.result.connect(self.print_output)
worker.signals.finished.connect(self.thread_complete)
# Execute
self.threadpool.start(worker)
You also often want to receive status information from long-running threads. This can be done by passing in callbacks to which your running code can send the information. You have two options here:
- Define new signals, allowing the handling to be performed using the event loop
- Use a regular Python function
In both cases, you'll need to pass these callbacks into your target function to be able to use them. The signal-based approach is used in the completed code below, where we pass a float back as an indicator of the thread's % progress.
The complete code
A complete working example is given below, showcasing the custom QRunnable worker together with the worker and progress signals. You should be able to easily adapt this code to any multithreaded application you develop:
import sys
import time
import traceback
from PySide6.QtCore import (
QObject,
QRunnable,
QThreadPool,
QTimer,
Signal,
Slot,
)
from PySide6.QtWidgets import (
QApplication,
QLabel,
QMainWindow,
QPushButton,
QVBoxLayout,
QWidget,
)
class WorkerSignals(QObject):
"""Signals from a running worker thread.
finished
No data
error
tuple (exctype, value, traceback.format_exc())
result
object data returned from processing, anything
progress
float indicating % progress
"""
finished = Signal()
error = Signal(tuple)
result = Signal(object)
progress = Signal(float)
class Worker(QRunnable):
"""Worker thread.
Inherits from QRunnable to handler worker thread setup, signals and wrap-up.
:param callback: The function callback to run on this worker thread.
Supplied args and
kwargs will be passed through to the runner.
:type callback: function
:param args: Arguments to pass to the callback function
:param kwargs: Keywords to pass to the callback function
"""
def __init__(self, fn, *args, **kwargs):
super().__init__()
self.fn = fn
self.args = args
self.kwargs = kwargs
self.signals = WorkerSignals()
# Add the callback to our kwargs
self.kwargs["progress_callback"] = self.signals.progress
@Slot()
def run(self):
try:
result = self.fn(*self.args, **self.kwargs)
except Exception:
traceback.print_exc()
exctype, value = sys.exc_info()[:2]
self.signals.error.emit((exctype, value, traceback.format_exc()))
else:
self.signals.result.emit(result)
finally:
self.signals.finished.emit()
class MainWindow(QMainWindow):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
self.counter = 0
layout = QVBoxLayout()
self.label = QLabel("Start")
button = QPushButton("DANGER!")
button.pressed.connect(self.oh_no)
layout.addWidget(self.label)
layout.addWidget(button)
w = QWidget()
w.setLayout(layout)
self.setCentralWidget(w)
self.show()
self.threadpool = QThreadPool()
thread_count = self.threadpool.maxThreadCount()
print(f"Multithreading with maximum {thread_count} threads")
self.timer = QTimer()
self.timer.setInterval(1000)
self.timer.timeout.connect(self.recurring_timer)
self.timer.start()
def progress_fn(self, n):
print(f"{n:.1f}% done")
def execute_this_fn(self, progress_callback):
for n in range(0, 5):
time.sleep(1)
progress_callback.emit(n * 100 / 4)
return "Done."
def print_output(self, s):
print(s)
def thread_complete(self):
print("THREAD COMPLETE!")
def oh_no(self):
# Pass the function to execute
worker = Worker(
self.execute_this_fn
) # Any other args, kwargs are passed to the run function
worker.signals.result.connect(self.print_output)
worker.signals.finished.connect(self.thread_complete)
worker.signals.progress.connect(self.progress_fn)
# Execute
self.threadpool.start(worker)
def recurring_timer(self):
self.counter += 1
self.label.setText(f"Counter: {self.counter}")
app = QApplication([])
window = MainWindow()
app.exec()
Caveats
You may have spotted a slight flaw in this master plan—we are still using the event loop (and the GUI thread) to process our workers' output.
This isn't a problem when we're simply tracking progress, completion, or returning metadata. However, if you have workers that return large amounts of data — e.g. loading large files, performing complex analysis and needing (large) results, or querying databases — passing this data back through the GUI thread may cause performance problems and is best avoided.
Similarly, if your application uses a large number of threads and Python result handlers, you may come up against the limitations of the GIL. As mentioned previously, when using threads execution of Python code is limited to a single thread at a time. The Python code that handles signals from your threads can be blocked by your workers and the other way around. Since blocking your slot functions blocks the event loop, this can directly impact GUI responsiveness.
In these cases, it is often better to investigate using a pure Python thread pool (e.g. concurrent futures) to keep your processing and thread-event handling further isolated from your GUI. However, note that any Python GUI code can block other Python code unless it's in a separate process.
March 25, 2025
PyCoder’s Weekly
Issue #674: LangGraph, Marimo, Django Template Components, and More (March 25, 2025)
#674 – MARCH 25, 2025
View in Browser »

{kind=link}
{kind=link}
{kind=link}
LangGraph: Build Stateful AI Agents in Python
LangGraph is a versatile Python library designed for stateful, cyclic, and multi-actor Large Language Model (LLM) applications. This tutorial will give you an overview of LangGraph fundamentals through hands-on examples, and the tools needed to build your own LLM workflows and agents in LangGraph.
REAL PYTHON
Reinventing Notebooks as Reusable Python Programs
Marimo is a Jupyter replacement that uses Python as its source instead of JSON, solving a lot of issues with notebooks. This article shows you why you might switch to marimo.
AKSHAY, MYLES, & MADISETTI
How to Build AI Agents With Python & Temporal

Join us on April 3 at 9am PST/12pm EST to learn how Temporal’s Python SDK powers an agentic AI workflow creation. We’ll start by covering how Temporal lets you orchestrate agentic AI, then transition to a live demo →
TEMPORAL sponsor
Django Template Components Are Slowly Coming
Django 5.2 brings the Simple Block tag which is very similar to React children, allowing templated components. This post shows several examples from Andy’s own code.
ANDREW MILLER
Articles & Tutorials
A Decade of Automating the Boring Stuff With Python
What goes into updating one of the most popular books about working with Python? After a decade of changes in the Python landscape, what projects, libraries, and skills are relevant to an office worker? This week on the show, we speak with previous guest Al Sweigart about the third edition of “Automate the Boring Stuff With Python.”
REAL PYTHON podcast
PyCon US: Travel Grants & Refund Policy
PyCon US offers travel grants to visitors. This post explains how they are decided. Also, with changing border requirements in the US, you may also be interested in the Refund Policy for International Attendees
PYCON.BLOGSPOT.COM
Using Structural Pattern Matching in Python
In this video course, you’ll learn how to harness the power of structural pattern matching in Python. You’ll explore the new syntax, delve into various pattern types, and find appropriate applications for pattern matching, all while identifying common pitfalls.
REAL PYTHON course
Smoke Test Your Django Admin Site
When writing code that uses the Django Admin, sometimes you forget to match things up. Since it is the Admin, who tests that? That doesn’t mean it won’t fail. This post shows you a general pytest function for checking that empty Admin pages work correctly.
JUSTIN DUKE
Python’s Instance, Class, and Static Methods Demystified
In this tutorial, you’ll compare Python’s instance methods, class methods, and static methods. You’ll gain an understanding of when and how to use each method type to write clear and maintainable object-oriented code.
REAL PYTHON
I Fear for the Unauthenticated Web
A short opinion post by Seth commenting on how companies scraping the web to build LLMs are causing real costs to users, and suggests you implement billing limits on your services.
SETH M LARSON
Django Query Optimization: Defer, Only, and Exclude
Database queries are usually the bottlenecks of most web apps. To minimize the amount of data fetched, you can leverage Django’s defer(), only(), and exclude() methods.
TESTDRIVEN.IO • Shared by Michael Herman
How to Use Async Agnostic Decorators in Python
Using decorators in a codebase that has both synchronous and asynchronous functions poses many challenges. One solution is to use generators. This post shows you how.
PATREON • Shared by Patreon Engineering
PEP 779: Criteria for Supported Status for Free-Threaded Python
PEP 703 (Making the Global Interpreter Lock Optional in CPython), described three phases of development. This PEP outlines the criteria to move between phases.
PYTHON.ORG
uv overtakes Poetry
Wagtail, the Django-based CMS, tracks download statistics including by which installation tool. Recently, uv overtook Poetry. This post shows the stats.
THIBAUD COLAS
Using Pyinstrument to Profile FastHTML Apps
A quick post with instructions on how to add profiling to your FastHTML app with pyinstrument.
DANIEL ROY GREENFIELD
Projects & Code
Events
Weekly Real Python Office Hours Q&A (Virtual)
March 26, 2025
REALPYTHON.COM
SPb Python Drinkup
March 27, 2025
MEETUP.COM
Python Leiden User Group
March 27, 2025
PYTHONLEIDEN.NL
PyLadies Amsterdam: Introduction to BDD in Python
March 31, 2025
MEETUP.COM
Happy Pythoning!
This was PyCoder’s Weekly Issue #674.
View in Browser »
[ Subscribe to 🐍 PyCoder’s Weekly 💌 – Get the best Python news, articles, and tutorials delivered to your inbox once a week >> Click here to learn more ]
TechBeamers Python
10 Viral Tips to Learn Python Instantly 🚀
Python is one of the most in-demand programming languages in 2025, powering AI, web development, automation, and more. Whether you’re a complete beginner or looking to sharpen your skills, you don’t need months to get started. If you want to learn Python instantly, these 10 viral, fast-track methods will help you grasp the fundamentals quickly […]